가상 네트워크란
일단 먼저, AWS VPC CNI를 이해하기 전에, 컨테이너의 가상 네트워크 먼저 알아야 한다 생각했다. 애초에 네트워크 지식이 전무하다싶었기 때문..
가장 흔히 사용하는 도커를 생각해보면, 도커에서 컨테이너 가상화란 ‘서버 한대를 여러 컨테이너로 격리’하는 기술이다.
비슷하게, 가상 네트워크란 서버 한대 안에서 여러 네트워크를 구성하는 기술이다.
하나의 서버 안에서 컨테이너끼리는 어떻게 통신을 하는지, 그리고 서버 외부와 컨테이너와는 어떻게 통신을 하는지를 도커의 가상 네트워크가 해결해준다.
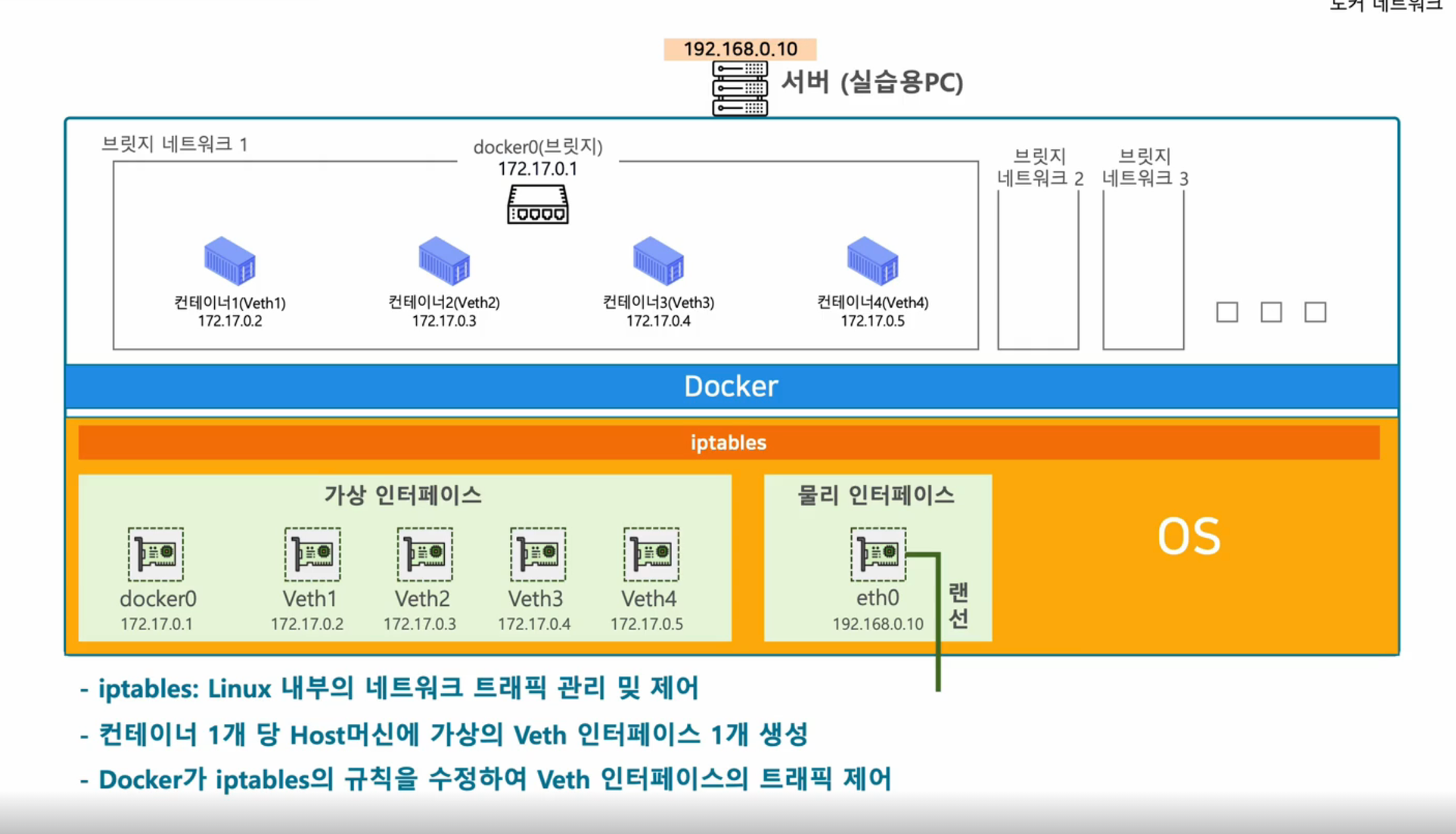
컨테이너를 실행시키면 도커는
- 가상의 네트워크인 브릿지 네트워크와 가상의 공유기인 브릿지를 생성한다. (보통 기본 브릿지는 172.17.0.1을 할당받음)
- 할당받은 브릿지 대역에서 컨테이너들에게 ip를 할당해줌.
이런 기술을 SDN(Software Defined Network)라고 한다.
- 컨테이너 간 통신
가상네트워크는 사실 컨테이너 간 통신, 그리고 외부와의 통신을 위해 탄생한 것이다.
컨테이너를 실행하기 위해, host os에는 가상 인터페이스가 생성되고, 브릿지 veth와 각 컨테이너 당 하나씩 veth가 생긴다.
각 컨테이너들 간의 통신을 위해 iptables에는 veth2가 도착지면 컨테이너2로 가라와 같은 규칙이 생성된다.
이렇게 같은 브릿지 네트워크 안에 있는 컨테이너들은 통신이 된다. 각 브릿지 네트워크는 구분되기 때문에 통신을 구분할 수도 있다.
그러나 도커는 CNI를 쓰지 않는다.(얘네는 CNM이라고 자기들만의 표준을 정해놓음 Container Network Model).
그래서 슬프게도 아래와 같은 명령은 동작하지 않는다.
docker run --network=cni-brdige nginx그렇다고 도커를 쿠버네티스에서 못 쓰는게 아니다. 알아서 쿠버네티스가 아래 명령어를 통해 cni 플러그인이 동작하도록 해준다고 한다.
docker run --network=none nginx
bridge add 234abcd /var/run/netns/234abcd
CNI
이제 가상네트워크가 뭔지 알았다. 도커가 CNI를 안쓴다는 것도 대충 알았다.
근데 EKS는 VPC CNI를 사용한다고 한다. 그래도 큰 상관은 없다. 표준만 다를 뿐 모두 '각각의 컨테이너들을 어떻게 통신시킬것인가' 를 위한 솔루션이다.
CNI는 Contianer Network Interface의 약자이다.
이게 왜 탄생했을까? (https://www.youtube.com/watch?v=l2BS_kuQxBA)
서로 다른 노드 안에 있는 컨테이너들은 같은 ip대역이 아니기에 가상 네트워크 브릿지를 만들고 NAT하여 서로 통신을 해왔는데, 서로 통신을 구현해주는 것이 CNI이이다.
여러 컨테이너 런타임들이 컨테이너 네트워크 통신 이슈를 해결하기 위해 각자의 방법으로 기술을 구현해왔다.

각각의 솔루션들을 하나의 표준으로 만든 것이 CNI이다.
로켓이든 쿠버네티스든
brdige add 컨테이너 네트워크네임스페이스를 하면 표준 cni 플러그인이 알아서 처리해준다.
AWS VPC CNI
가시다님과 하는 스터디는 EKS이므로 AWS VPC CNI를 사용한다.
위처럼 표준 CNI를 각자의 상황에 맞게 컨테이너 런타임들은 사용해옸다. EKS는 AWS가 구현한 CNI를 사용한다.
특징은 파드의 IP 네트워크 대역과 워커노드의 IP 대역이 같기에 패킷을 오버레이 통신하지 않고, 직접통신을 지원한다.
따라서 속도 면에서 효율적이다.

[실습] 보조 IPv4 주소를 파드가 사용하는지
아래는 워커노드 하나의 네트워크정보인데, private ip 2개를 할당받았는데 이건 eni2개를 받은것임.(즉, 랜카드가 두개임).
secondart ip는 10개인데, 이는 eni 1개당 보조ip를 5개씩 할당받기 때문이다.


위 두스샷을 보면, 192.168.3.62가 ec2의 secondary private 주소로 할당되어 있고, 이 주소가 coredns에서 사용중이다.
또한 이 주소는 노드의 ip와 같은 대역대를 사용중임을 알 수 있다.
즉, 파드가 노드와 같은 대역의 ip를 사용한다.
[실습] 네트워크 네임스페이스 구분이 어떻게 되는지
coredns 파드의 ip 2개 모두 node의 eni로 라우팅이 된다.
(manager@myeks:N/A) [root@myeks-bastion-EC2 ~]# kubectl get pod -n kube-system -l k8s-app=kube-dns -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
coredns-55474bf7b9-gxmks 1/1 Running 0 89m 192.168.3.108 ip-192-168-3-229.ap-northeast-2.compute.internal <none> <none>
coredns-55474bf7b9-v5g9p 1/1 Running 0 89m 192.168.1.146 ip-192-168-1-226.ap-northeast-2.compute.internal <none> <none>아래 스샷 보면, 위에서 검색한 coredns팟 ip인 192.168.3.108랑 192.168.1.146모두 각자의 eni로 라우팅이 되는것을 볼 수있다.

그런데 다른 파드를 보면, 노드의 ip(192.168.1.226)를 그대로 사용한다. (아니 누구는 따로 ip쓰고 누구는 노드의 ip를 바로 쓰네?)
(manager@myeks:N/A) [root@myeks-bastion-EC2 ~]# k get pod aws-node-cx7v5 -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
aws-node-cx7v5 2/2 Running 0 97m 192.168.1.226 ip-192-168-1-226.ap-northeast-2.compute.internal <none> <none>아래보면 ip두개 할당받았는데 위에 aws-node 파드가 이 ip를 그대로 쓰고 있음

coredns의 ip는 (내 실습기준 ip)192.168.1.146인데, 이는 라우팅이 veth(eni6d8874c…)로 되어있고, 이는 노드의 eth0으로 향함. 반면 다른 파드(aws-node, kube-proxy)는 ip가 노드의 eth0과 같다.
위 내용은 아래 그림으로 요약된다.
즉, 서로 속한 네트워크 네임스페이스가 다르게 설정되어 있기 때문임.

[실습]팟의 veth와 외부에서 호출하는 ip 연결 확인
팟에 직접 들어가서 네트워크를 확인하면
ip -c addr
kubectl get pod할 때 보이는 ip와 파드의 veth가 연결되어있음을 알 수 있다.

[실습]서로 다른 노드들의 파드 간 통신
팟안에서 다른 노드 팟의 veth ip를 이용해 통신이 된다.
다른 노드팟 192.168.3.230에다가 핑을 날려보면, 된다!

dns도 확인하면 신기한데, nameserver가 dns 팟이있는 서비스의 cluster ip이다!
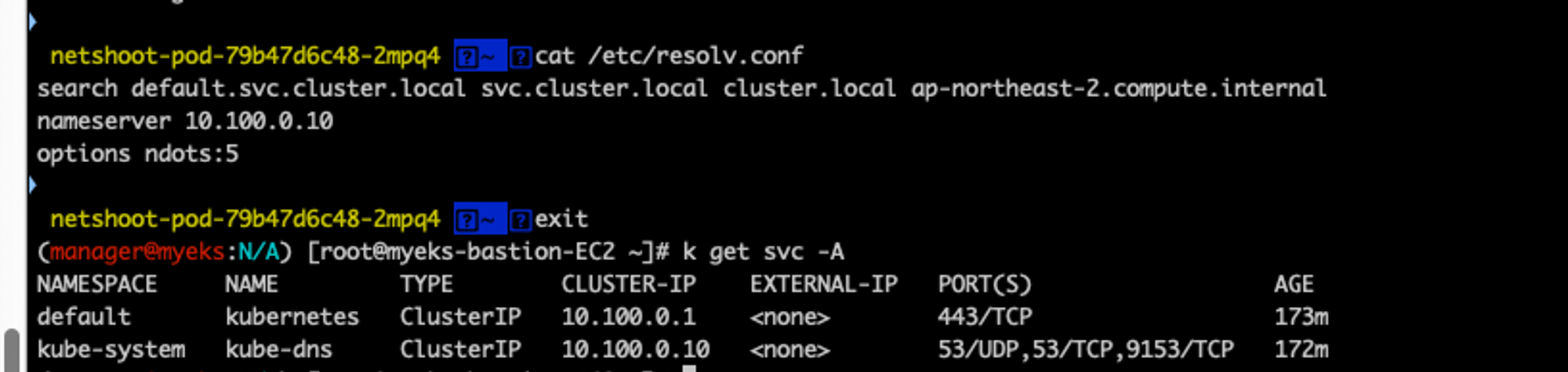
[실습]팟이 외부통신할때에는 어떤 ip로 nat이 될까?
public ip가 똑같이 찍힌다! 즉, 팟이 외부로 나갈때에는 속한 노드의 eth0의 public ip로 nat이 된다.

Service
외부에서 내부로 접근해보자.
팟은 언제든 죽었다 살아날 수 있기에 ip가 고정되지 않는다. 이 문제를 서비스라는 놈을 고정 진입점을 만들고 부하분선을 하며 해결할 수 있다.
어떤 기술로 구현했느냐에 따라 방식이 조금씩은 다르다. 스터디 실습환경은 AWS이므로, 로드밸런서를 사용한다.
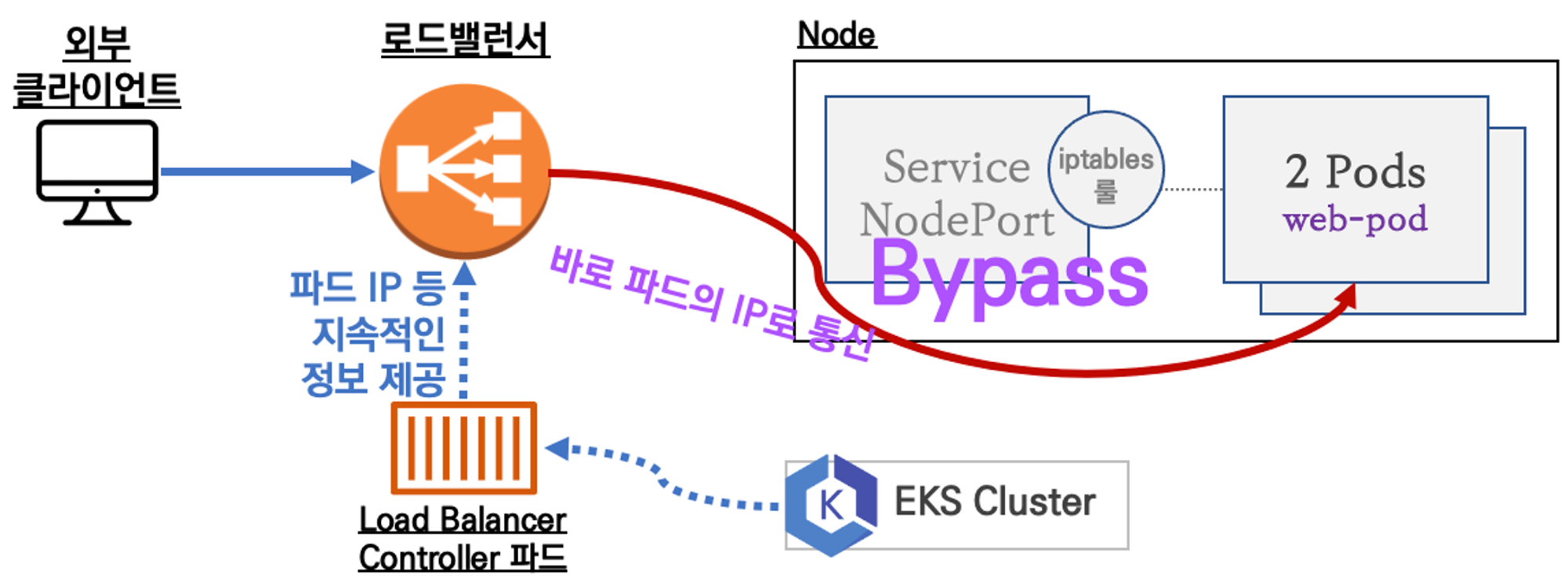
AWS에서 서비스를 로드밸런서를 한다면, 온프레미스 로드밸런서 장비와 달리, 노드포트를 거치지 않는다.
아래 첫째사진은 온프레미스이며, 두번째 사진이 aws이다.

Load Balancer Controller파드가 nlb에게 지속적으로 ip정보를 줘서 그 ip로 맞빠로 통신을 한다. 이것이 가능한 것 모두 AWS CNI덕분에 ip가 같은 대역이기 때문이다.
[실습]
- OIDC 생성
일단, Load Balancer가 aws의 자원인 lb를 생성할 수 있어야 하므로 권한이 있어야 한다.
그러기 위해서는 OIDC를 통해 aws와 쿠버네티스 간에 뭔가 왔다갔다 할 수 있는 다리를 만들어야 한다.
aws eks describe-cluster --name $CLUSTER_NAME --query "cluster.identity.oidc.issuer" --output text
사실 eks 콘솔에서 아래처럼 확인도 가능하다.

- IAM Policy 생성
이렇게 aws iam권한을 갖다 쓸수있게 해놨으니, 갖다 쓸 iam policy을 생성한다.
스터디에서 제공한 권한을 다운받아 생성했다.: https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/v2.5.4/docs/install/iam_policy.json

- Service Account 와 IAM role생성
이제 AWS LoadBalancer Controller가 IAM을 갖다 쓸 수 있도록 ServiceAccount를 생성한다. 서비스 어카운트에다가 아까 iam에서 만든 policy를 포함하는 iam role을 생성하고 서로연결하는 것이다.
eksctl create iamserviceaccount --cluster=$CLUSTER_NAME --namespace=kube-system --name=aws-load-balancer-controller --role-name AmazonEKSLoadBalancerControllerRole \
--attach-policy-arn=arn:aws:iam::$ACCOUNT_ID:policy/AWSLoadBalancerControllerIAMPolicy --override-existing-serviceaccounts --approve
클라우드 스택으로 자원이 생성된 걸 볼 수 있다.

롤도 생겼다.

IRSA정보 확인하여 로드밸런서 컨트롤러가 이 role을 쓸 수 있다는 걸 확인가능하다.
eksctl get iamserviceaccount --cluster $CLUSTER_NAME
생성한 service account에도 이 role 정보가 보인다.
kubectl get serviceaccounts -n kube-system aws-load-balancer-controller -o yaml | yh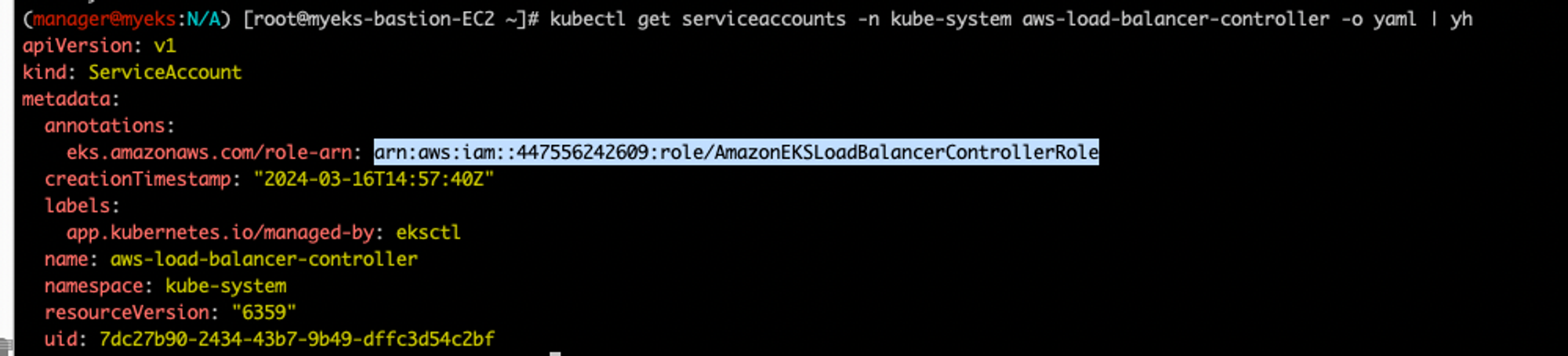
aws-load-balancer-controller 와 targetgroup binding생성
이제 권한이 있으니, 로드밸런서 컨트롤러를 helm으로 설치해보자. helm이 알아서 다해줌. 단 위에서 serviceaccount들은 만들었으니 --set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller 를 오버라이드해준다.
얘가 바로 로드밸런서를 생성하고 조작하는 애이다.
# Helm Chart 설치
helm repo add eks https://aws.github.io/eks-charts
helm repo update
helm install aws-load-balancer-controller eks/aws-load-balancer-controller -n kube-system --set clusterName=$CLUSTER_NAME \
--set serviceAccount.create=false --set serviceAccount.name=aws-load-balancer-controller만든 후, crd(custom resource definition)를 확인해보면 내가 방금 추가한 Ingress어쩌구랑 targetgroupbindings가 추가되어있다. 얘네가 로드밸런서의 targetgroup을 조작하는 애들이다.

aws 로드밸런서 생성
이제 드디어 aws 로드밸런서를 쿠버네티스를 통해서 만들자
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/2/echo-service-nlb.yaml
cat echo-service-nlb.yaml | yh
kubectl apply -f echo-service-nlb.yaml
서비스의 spec.loadBalancerClass: service.k8s.aws/nlb 설정이 aws에서 nlb를 생성하도록 한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-echo
spec:
replicas: 2
selector:
matchLabels:
app: deploy-websrv
template:
metadata:
labels:
app: deploy-websrv
spec:
terminationGracePeriodSeconds: 0
containers:
- name: akos-websrv
image: k8s.gcr.io/echoserver:1.5
ports:
- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:
name: svc-nlb-ip-type
annotations:
service.beta.kubernetes.io/aws-load-balancer-nlb-target-type: ip
service.beta.kubernetes.io/aws-load-balancer-scheme: internet-facing
service.beta.kubernetes.io/aws-load-balancer-healthcheck-port: "8080"
service.beta.kubernetes.io/aws-load-balancer-cross-zone-load-balancing-enabled: "true"
spec:
ports:
- port: 80
targetPort: 8080
protocol: TCP
type: LoadBalancer
loadBalancerClass: service.k8s.aws/nlb
selector:
app: deploy-websrv진짜로 nlb가 생성되었다. 타입도 network 확인

타겟그룹바인딩이 확인가능한데,
kubectl get targetgroupbindings -o json | jqaws의 타겟그룹 arn정보와 security group정보 등을 알 수 있다.

만들어진 lb에 대한 정보도 보인다.
aws elbv2 describe-load-balancers | jq
여기서 특징이, targetgroup의 ip가 파드의 ip와 똑같다.
모두 192.168.3.198,192.168.1.156 이다.


이게 바로 위 그림에 나온, 노드포트를 거치지 않고 바로 파드로 가는걸 보여준다.
nlb의 주소를 확인해 접근하면 잘 된다!

부하분산 확인
로드밸런싱도 잘 되는지 100번 접속해보면, 잘 나뉜다!
# 분산 접속 확인
NLB=$(kubectl get svc svc-nlb-ip-type -o jsonpath={.status.loadBalancer.ingress[0].hostname})
curl -s $NLB
for i in {1..100}; do curl -s $NLB | grep Hostname ; done | sort | uniq -c | sort -nr
파드 스케일
현재 파드가 2개인데,

1개로 줄여보자.
kubectl scale deployment deploy-echo --replicas=1
타겟그룹도 draining이 된다.(while true; do aws elbv2 describe-target-health --target-group-arn $TARGET_GROUP_ARN --output text; echo; done)

100번 서비스에 접근하면 아까와 달리 한곳에만 모두 통신이 간다.

이번엔 3개로 늘려보자
kubectl scale deployment deploy-echo --replicas=3
팟이 생성되고
타겟그룹도 생성되는게 보인다.
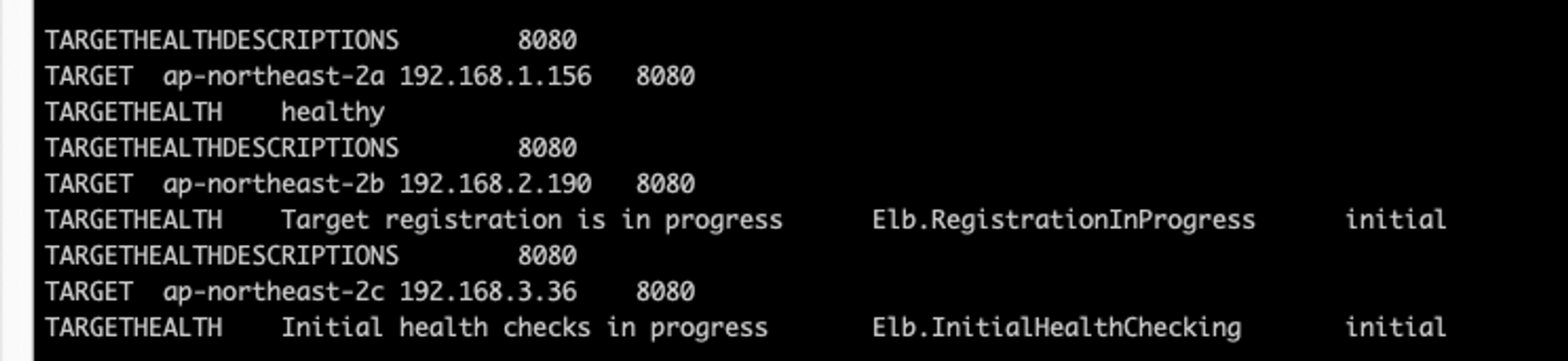
3곳으로 부하분산 되는것도 확인된다.

Ingress
서비스와 거의 유사하지만, 서비스가 4계층에서 동작한다면, 얘는 7계층에서 동작한다. 웹 통신(http/https)에 특화되어있다.

인그레스도 생성해보자.
curl -s -O https://raw.githubusercontent.com/gasida/PKOS/main/3/ingress1.yaml
kubectl apply -f ingress1.yaml
kind: Ingress가 있고, spec.ingressClassName: alb임을 확인할 수 있다.
apiVersion: v1
kind: Namespace
metadata:
name: game-2048
---
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: game-2048
name: deployment-2048
spec:
selector:
matchLabels:
app.kubernetes.io/name: app-2048
replicas: 2
template:
metadata:
labels:
app.kubernetes.io/name: app-2048
spec:
containers:
- image: public.ecr.aws/l6m2t8p7/docker-2048:latest
imagePullPolicy: Always
name: app-2048
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
namespace: game-2048
name: service-2048
spec:
ports:
- port: 80
targetPort: 80
protocol: TCP
type: NodePort
selector:
app.kubernetes.io/name: app-2048
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
namespace: game-2048
name: ingress-2048
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
spec:
ingressClassName: alb
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: service-2048
port:
number: 80kubectl get ingress를 하면 address가 뜬다.

이게 alb의 주소이다.

접속이 된다!

얘도 마찬가지로 pod의 ip가 targetgroup의 target에 매핑이 되어있음을 확인할 수 있다.


External dns
도메인으로 접근을 하면 자동으로 서비스/인그레스를 사용해서 접근되도록 알아서 Route53에 A레코드를 자동 생성/삭제를 해주는 기능이다.

현재 내 도메인의 레코드에는 별거없음.

일단 실습위해
external dns를 아래처럼 설치를 한다.(링크:https://raw.githubusercontent.com/gasida/PKOS/main/aews/externaldns.yaml)
중요한 건 아래 spec.containers.args이다. 이걸로 연결할 서비스를 찾고 도메인을 연결해주는 것 같다.
spec:
serviceAccountName: external-dns
containers:
- name: external-dns
image: registry.k8s.io/external-dns/external-dns:v0.13.4
args:
- --source=service
- --source=ingress
- --domain-filter=${MyDomain} # will make ExternalDNS see only the hosted zones matching provided domain, omit to process all available hosted zones
- --provider=aws
#- --policy=upsert-only # would prevent ExternalDNS from deleting any records, omit to enable full synchronization
- --aws-zone-type=public # only look at public hosted zones (valid values are public, private or no value for both)
- --registry=txt
- --txt-owner-id=${MyDnzHostedZoneId}
env:
- name: AWS_DEFAULT_REGION
value: ap-northeast-2 # change to region where EKS is installed위에 있는${}값들을 내 정보로 치환해주면서 배포를 해보자

아래는 배포된 external dns 팟인데, spec.containers.args에 있는 domain-filter값과 txt-owner 호스트존값으로 바뀐 결과이다.

이제 서비스와 디플로이먼트를 배포를 한다.
그 후 서비스의 어노테이션에 다음을 추가를 해야, external dns파드가 이 서비스를 감지하고 자동으로 route53에 레코드를 등록해준다.
kubectl annotate service tetris "external-dns.alpha.kubernetes.io/hostname=tetris.$MyDomain"
Network Policies
기본적으로 eks vpc cni에서 모든 팟은 같은 ip대역을 공유하기에 모두 접근이 가능하다.
그러나, 서로 다르거나 굳이 접근하지 않아도 되는 팟끼리 모두 접근이 되는 것은 바람직하지 않다.
이를 해결하기 위해 만약 노드(ec2)에다 sg를 걸어버린다면, 오토스케일이 되거나 컨테이너가 죽거나 생성될 때 원하지 않는 결과가 나온다. 물론 조정할 수는 있겠지만 복잡할 것이다.
즉 ec2에 대한 sg로는 각각의 팟을 통제할 수 없다.
이를 해결하기 위해 AWS SG for Pods가 나왔다고 한다.

aws의 sg처럼, 각각의 팟에 대해 통제를 하는 개념인데, 구축은 아래 설명대로 하면 된다고 한다.
You can enable security groups for Pods by setting ENABLE_POD_ENI=true for VPC CNI. Once enabled, the “VPC Resource Controller“ running on the control plane (managed by EKS) creates and attaches a trunk interface called “aws-k8s-trunk-eni“ to the node. The trunk interface acts as a standard network interface attached to the instance. To manage trunk interfaces, you must add the AmazonEKSVPCResourceController managed policy to the cluster role that goes with your Amazon EKS cluster.
The controller also creates branch interfaces named "aws-k8s-branch-eni" and associates them with the trunk interface. Pods are assigned a security group using the SecurityGroupPolicy custom resource and are associated with a branch interface. Since security groups are specified with network interfaces, we are now able to schedule Pods requiring specific security groups on these additional network interfaces. Review the EKS User Guide Section on Security Groups for Pods, including deployment prerequisites.
Network Policies with VPC CNI
가시다님 스터디에서는 Network Policies with VPC CNI를 실습했다.
처음 eks 생성시 만든 yaml의 addon에서 enableNetworkPolicy: "true" 가 되어야 노드들의 args에 network policy를 활성화할 수 있게 된다.
addons:
- name: vpc-cni # no version is specified so it deploys the default version
version: latest # auto discovers the latest available
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
configurationValues: |-
enableNetworkPolicy: "true"
- name: kube-proxy
version: latest
- name: coredns
version: latest아래는 노드에 추가된 정보.

network policy는 Network Policy Controller가 만들어주는데, aws-network-policy-agent가 있음을 확인할 수 있다.
(manager@myeks:N/A) [root@myeks-bastion-EC2 ~]# kubectl get ds aws-node -n kube-system -o yaml | grep -i image:
image: 602401143452.dkr.ecr.ap-northeast-2.amazonaws.com/amazon-k8s-cni:v1.16.4-eksbuild.2
image: 602401143452.dkr.ecr.ap-northeast-2.amazonaws.com/amazon/aws-network-policy-agent:v1.0.8-eksbuild.1
image: 602401143452.dkr.ecr.ap-northeast-2.amazonaws.com/amazon-k8s-cni-init:v1.16.4-eksbuild.2
또한 이 기술은 ebpf로 구현이 된다고 하는데, 이것도 구현이 되어있음을 확인가능하다.(type bpf 확인!)
(manager@myeks:N/A) [root@myeks-bastion-EC2 ~]# ssh ec2-user@$N1 mount | grep -i bpf
none on /sys/fs/bpf type bpf (rw,nosuid,nodev,noexec,relatime,mode=700)
[실습] network namespace 별 접근 통제하기
현재는 모든 팟에서 Demo-App 팟으로 접근이 된다. 네임스페이스 별로 통제를 해보자.

먼저 디폴트 ns에는 3개의 팟이 있다.
(manager@myeks:N/A) [root@myeks-bastion-EC2 eks-network-policy-examples]# kubectl get pod,svc
NAME READY STATUS RESTARTS AGE
pod/client-one 1/1 Running 0 115s
pod/client-two 1/1 Running 0 115s
pod/demo-app-6fd76f694b-qspc2 1/1 Running 0 115s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/demo-app ClusterIP 10.100.222.213 <none> 80/TCP 116s
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 55m
다른 ns(another ns)에는 다른 2개의 팟이 있다.
(manager@myeks:N/A) [root@myeks-bastion-EC2 eks-network-policy-examples]# kubectl get pod,svc -n another-ns
NAME READY STATUS RESTARTS AGE
pod/another-client-one 1/1 Running 0 3m
pod/another-client-two 1/1 Running 0 3m각 팟에서 demo-app에다가 curl을 날리면 통신이 된다. 참고로, 서로 다른 ns에서 통신을 하려면 ns를 명시해줘야 한다.
kubectl exec -it another-client-one -n another-ns -- curl demo-app. (이거 안됨)
kubectl exec -it another-client-one -n another-ns -- curl demo-app.default (이게 됨)
또는 svc에 찔러도 됨
kubectl exec -it another-client-two -n another-ns -- curl demo-app.default.svc
이제 모든 트래픽을 거부해보자
(manager@myeks:N/A) [root@myeks-bastion-EC2 eks-network-policy-examples]# cat advanced/policies/01-deny-all-ingress.yaml | yh
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: demo-app-deny-all
spec:
podSelector:
matchLabels:
app: demo-app
policyTypes:
- IngresspolicyTypes:에 Ingress만 적고 아무 룰이 없으면 다 차단한다는 뜻이다.
실행하고 생성된 리소스(NetworkPolicy)가 있나 보면 떠있는거 확인이 된다.
(manager@myeks:N/A) [root@myeks-bastion-EC2 eks-network-policy-examples]# kubectl get networkpolicy
NAME POD-SELECTOR AGE
demo-app-deny-all app=demo-app 5s통신이 계속되다가 생성한 즉시(아래 스샷기준 23:44:55에는 되다가 23:44:57부터) 통신이 막히는걸 알 수 있다.

정책을 다시 삭제하면 바로 다시 통신이 된다.

같은 ns의 클라이언트1으로부터만 수신을 허용해보자. 이때 팔러시는 아래와 같다.
spec.ingress.from.podSelector.matchLabels통해 app: client-one만 받도록 제어가 된다.
(manager@myeks:N/A) [root@myeks-bastion-EC2 eks-network-policy-examples]# cat advanced/policies/03-allow-ingress-from-samens-client-one.yaml | yh
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: demo-app-allow-samens-client-one
spec:
podSelector:
matchLabels:
app: demo-app
ingress:
- from:
- podSelector:
matchLabels:
app: client-one이를 적용하면 바로 통신이 된다. (23:52:19이후부터 통신이 된다)

그러나 역시 의도한대로 클라이언트2에서는 수신이 안됨.

이제 egress를 해보자!
이번엔 위와 달리 spec.policyTypes가 Egress이다. app: client-one 에 대해서만 적용해보자.
즉, 클라이언트1은 아웃바운드를 하지 못하게 됨.
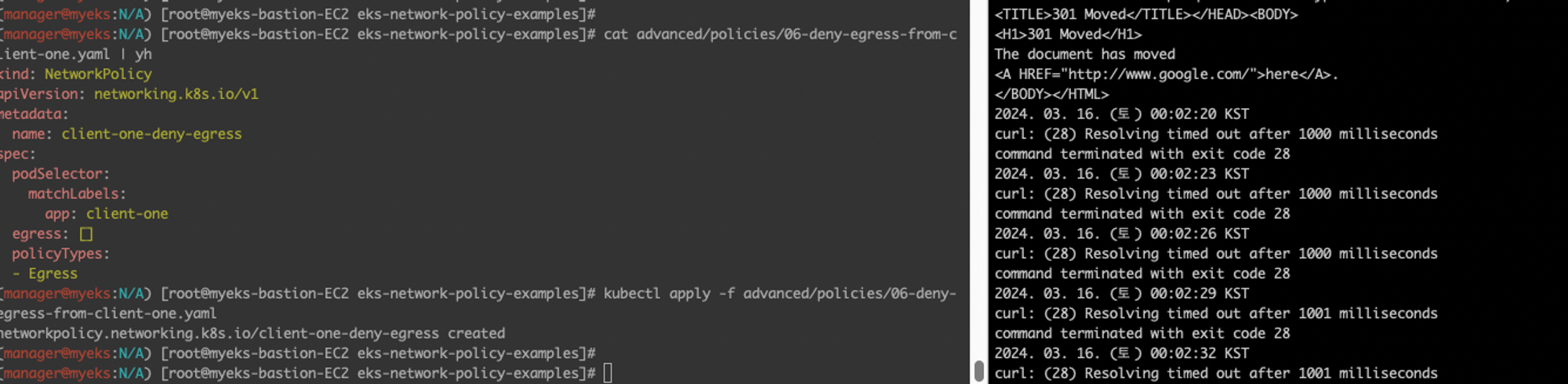
(manager@myeks:N/A) [root@myeks-bastion-EC2 eks-network-policy-examples]# cat advanced/policies/06-deny-egress-from-client-one.yaml | yh
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: client-one-deny-egress
spec:
podSelector:
matchLabels:
app: client-one
egress: []
policyTypes:
- Egress바로 타임아웃됨 확인!
특정 포트에 대해서만도 적용이 가능하다.
spec.egress.to.ports 속성으로 제어가 된다.
(manager@myeks:N/A) [root@myeks-bastion-EC2 eks-network-policy-examples]# cat advanced/policies/08-allow-egress-to-demo-app.yaml | yh
kind: NetworkPolicy
apiVersion: networking.k8s.io/v1
metadata:
name: client-one-allow-egress-demo-app
spec:
podSelector:
matchLabels:
app: client-one
egress:
- to:
- namespaceSelector:
matchLabels:
kubernetes.io/metadata.name: kube-system
podSelector:
matchLabels:
k8s-app: kube-dns
ports:
- port: 53
protocol: UDP
- to:
- podSelector:
matchLabels:
app: demo-app
ports:
- port: 80
protocol: TCP
역시 적용하면 바로 통신이 된다.(00:30:20 이후부터 통신이 됨이 보인다)

소감
내가 기본기가 탄탄하지도 않고, 경력도 아직 2년이 되지 않아 네트워크는 너무 어려웠다. 처음 이렇게 딥하게 보는거라, 정말 이해를 잘 못하는 것들이 너무 많아 좀 답답했다. 여러번 복습하는 것이 답이란 생각에, 집에 가자마자 동영상을 다시 보며 실습을 해야겠단 생각으로 슬랙으로 미리 eks를 띄우는 것도 만들기도 함...
리눅스 기본 네트워크 지식을 틈틈히 일하며 공부를 해야겠다. 스터디에서 제공해준 기본 명령어들을 기준으로 관련된 지식을 넓혀나가자.
'개발삽질 > 잡다한 개발기록' 카테고리의 다른 글
| [EKS 스터디-5] EKS Autoscaling (0) | 2024.04.03 |
|---|---|
| [EKS 스터디-4] EKS Observability (0) | 2024.03.26 |
| [EKS 스터디-1] 클러스터 구조와 기본사용법 (0) | 2024.03.06 |
| [sql]프로그래머스 sql문제정리1(select, 집계함수, group by) (0) | 2022.03.11 |
| [알고리즘] DFS - 경로탐색 (0) | 2022.01.25 |



댓글