실습환경 배포
난 슬랙으로 쏴서 퇴근길에, 또는 운동하고 샤워하면서 미리 클라우드포메이션을 구성하고 싶다.

저번 주차와 마찬가지로, 난 lambda로 cloudformation yaml을 실행하도록 구성하였다. 매주 버전이 달라지기에 , event payload에 version을 받아 스터디에서 제공해주는 yaml파일 맨 뒤에만 수정해주었다.
def lambda_handler(event, context):
client = boto3.client('cloudformation')
key_name = os.environ['key_name']
access_key = os.environ['access_key']
secret_key = os.environ['secret_key']
sg_cidr = event['sg_cidr']
version = event['version']
# print(f"key_name:{key_name}, access_key:{access_key}, secret_key:{secret_key}, sg_cidr:{sg_cidr}")
client.create_stack(
StackName = 'myeks',
TemplateURL='https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/eks-oneclick'+version+'.yaml',
Parameters=[
{
'ParameterKey': 'KeyName',
'ParameterValue': key_name,
},
{
'ParameterKey': 'MyIamUserAccessKeyID',
'ParameterValue': access_key,
},
{
'ParameterKey': 'MyIamUserSecretAccessKey',
'ParameterValue': secret_key,
},
{
'ParameterKey': 'SgIngressSshCidr',
'ParameterValue': sg_cidr,
}
]
)
Logging in EKS
EKS에서 컨트롤플레인은 AWS가 관리하므로 아래 콘솔화면에서 클라우드와치 설정을 켜주면 로깅이 된다.
모두 로깅을 키면, 아래처럼 클라우드와치 로그그룹 별로 저장이 된다.
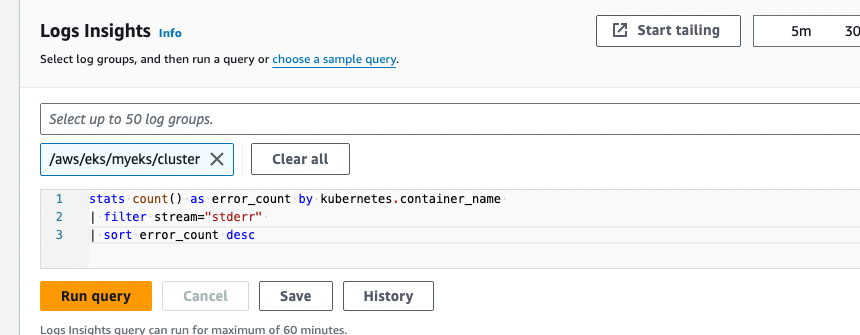
로그 인사이트에서 아래처럼 쿼리를 날리기도 가능하다.
파드 로깅
Nginx 웹서버의 로깅을 해보자
헬름으로 설치를 한다.
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami그리고 아래처럼 service와 ingress를 설정한 후
# 파라미터 파일 생성 : 인증서 ARN 지정하지 않아도 가능! 혹시 https 리스너 설정 안 될 경우 인증서 설정 추가(주석 제거)해서 배포 할 것
cat <<EOT > nginx-values.yaml
service:
type: NodePort
networkPolicy:
enabled: false
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
pathType: Prefix
path: /
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
#alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat nginx-values.yaml | yh배포를 하면
helm install nginx bitnami/nginx --version 15.14.0 -f nginx-values.yaml내 route53에 인그레스가 추가되면서 잘 접속이 된다.

자 이제 접속을 계속하며 로그를 봐보면,
# 왼쪽화면
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done# 오른쪽화면
# 로그 모니터링
kubectl logs deploy/nginx -f아래처럼 로그가 쌓이는 걸 확인할 수 있는데, 이 원리는 무엇일까?
로그가 쌓이는 곳의 위치에 가보면 아래와 같은데
kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/

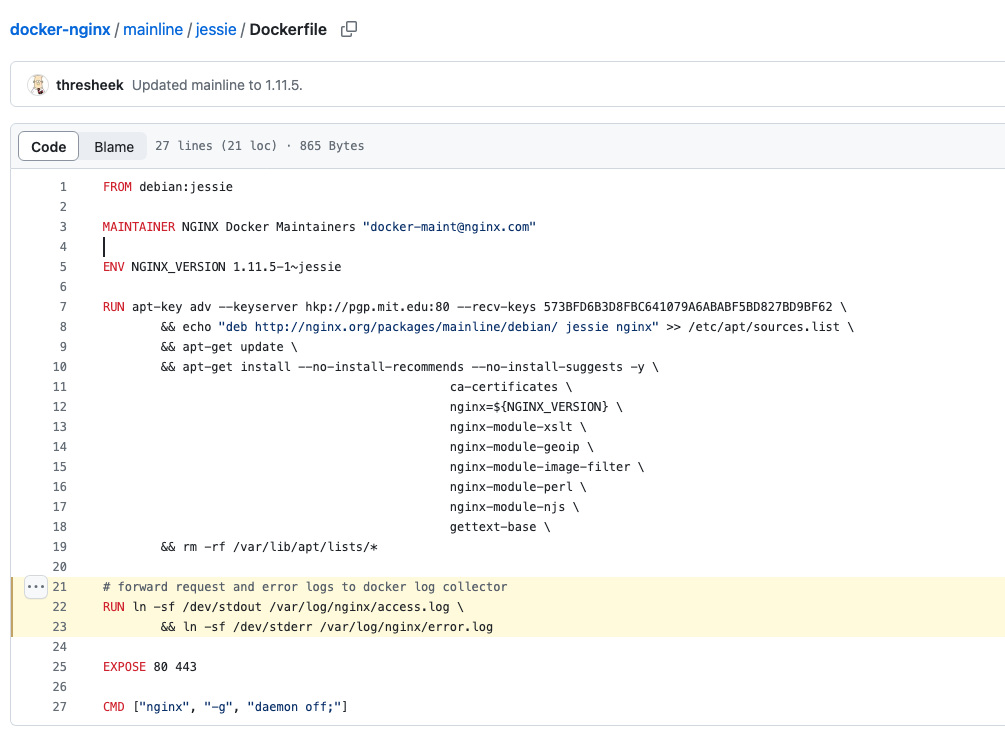
사실 nginx 이미지를 만들때 도커파일에 링크를 만들어놓은 것이다. 덕분에 docker logs를 하면 로그를 볼 수 있게 된다.
https://github.com/nginxinc/docker-nginx/blob/8921999083def7ba43a06fabd5f80e4406651353/mainline/jessie/Dockerfile#L21-L23
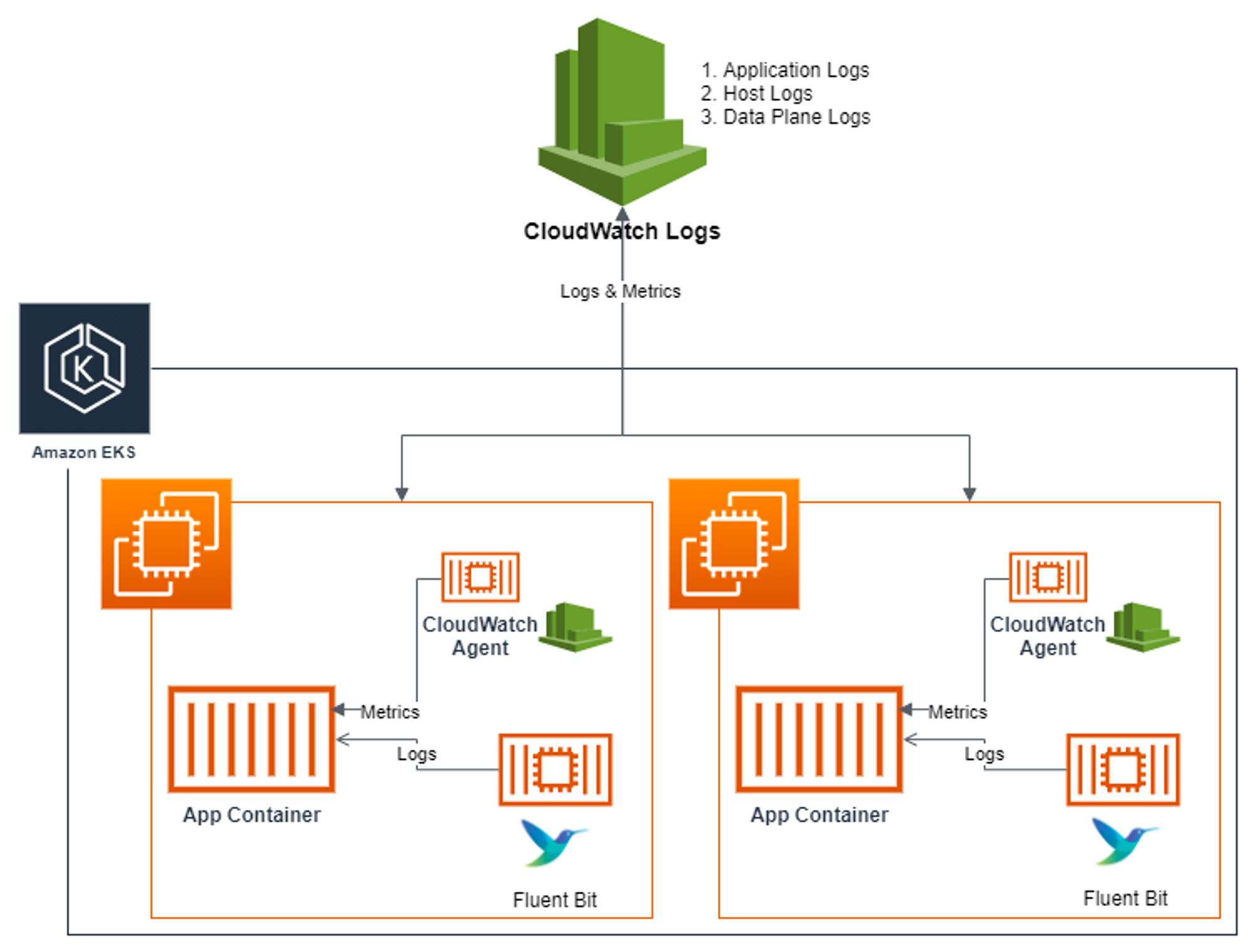
이렇게 컨테이너 안에 로그가 쌓이긴 하지만, 용량 제한도 있고, 보안감사 등의 이유로 중앙에 쌓아야할 니즈가 생기는데, 이를 위해 아래 내용처럼 클라우드와치와 플루언트 빗 등을 사용하게 된다.
Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
아키텍쳐마다 다를 순 있지만, Fluent Bit과 CloudWatch Agent 파드가 각각 배포되어서 앱 컨테이너의 정보를 수집하는 것이다.
실습 전에 노드의 로그를 확인해보자
Application 로그
어플리케이션 로그는 All log files in /var/log/containers → 심볼릭 링크 /var/log/pods/<컨테이너> 이런식이다.
ssh ec2-user@$N1 sudo ls -al /var/log/containers
아래처럼 직접 해당 파드의 로그를 보면 정말 로그가 보인다.

Host 로그
호스트의 로그도 아래 경로에 보인다.
ssh ec2-user@$N1 sudo ls -la /var/log/
DataPlane 로그
# 로그 위치 확인
#ssh ec2-user@$N1 sudo tree /var/log/journal -L 1
#ssh ec2-user@$N1 sudo ls -la /var/log/journal
for node in $N1 $N2 $N3; do echo ">>>>> $node <<<<<"; ssh ec2-user@$node sudo tree /var/log/journal -L 1; echo; done
# 저널 로그 확인 - 링크
ssh ec2-user@$N3 sudo journalctl -x -n 200
ssh ec2-user@$N3 sudo journalctl -f
CloudWatch Container observability 설치
aws eks create-addon --cluster-name $CLUSTER_NAME --addon-name amazon-cloudwatch-observability
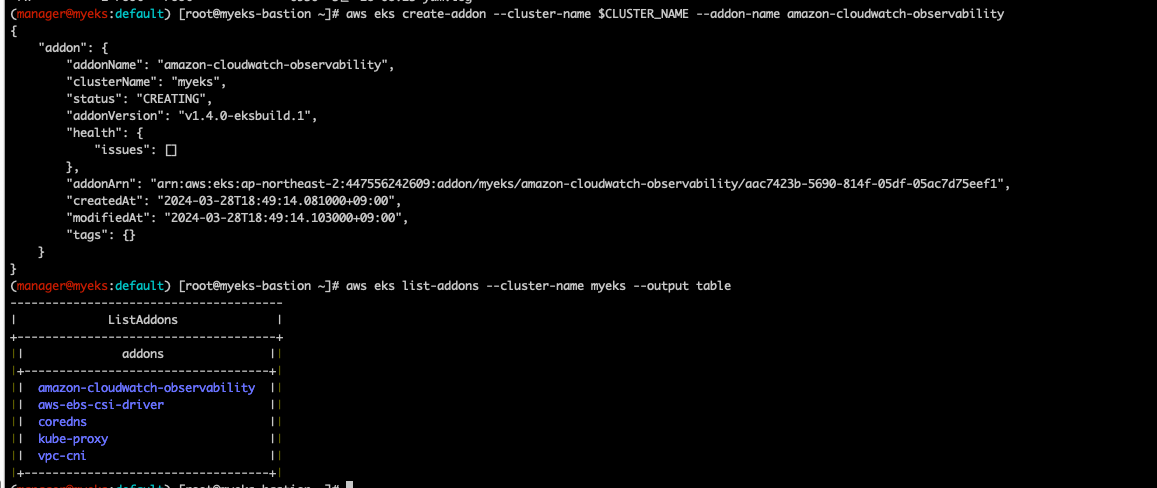
설치된걸 보면 Cloudwatch와 Fluentbit agent들이 데몬셋으로 떠있음을 볼 수 있다.
kubectl get ds,pod,cm,sa,amazoncloudwatchagent -n amazon-cloudwatch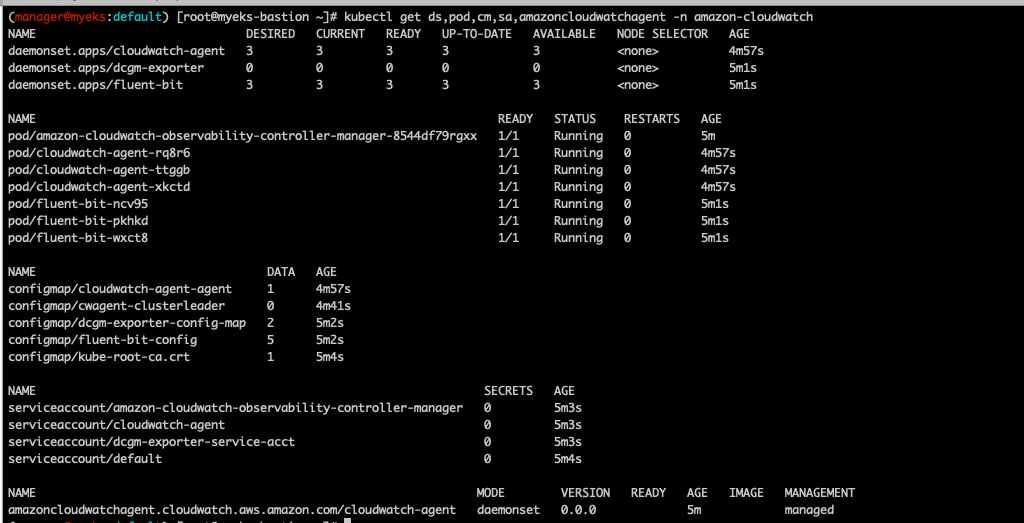
CloudWatch agent와 Fluentbit는 어디서 로그를 가져오는가
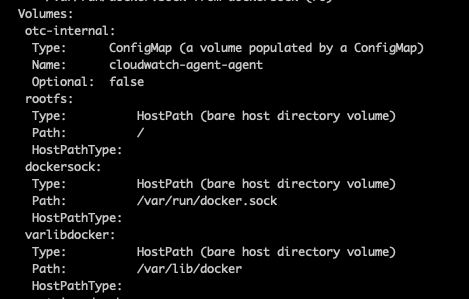
kubectl describe -n amazon-cloudwatch ds cloudwatch-agent아래처럼 호스트노드의 볼륨을 마운트해서 사용함을 알 수 있다.
주의햅서 봐야하는건, root 파일시스템을 호스트의 루트패스를 박아버렸는데 이러면 보안에 취약해진다. 파드가 털리면 호스트노드가 다 털리기 때문이다. 암튼 클라우드와치는 아래처럼 노드의 아래정보를 가져다가 사용함을 알 수 있다.
application설정부분을 보면,
Path에서 호스트패스의 로그 저장장소의 모든 로그를 수집함을 알 수 있다.
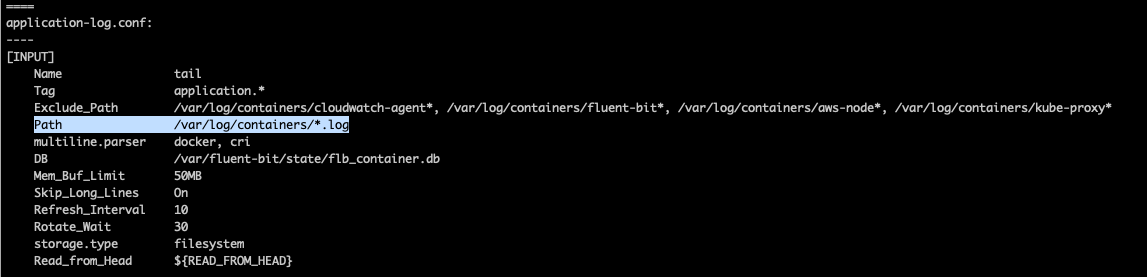
필터를 나름대로 하고
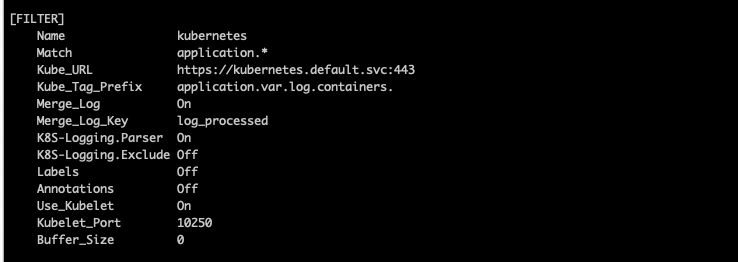
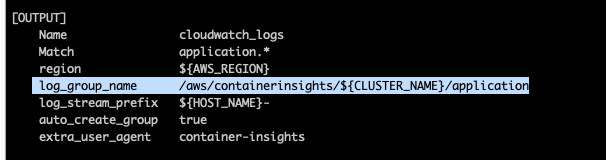
아웃풋으로 클라우드와치의 아래 로그그룹에 저장하도록 설정이 되어있다.
Fluent Bit도 아래처럼 볼륨이 마운트되어서 로그수집하는 경로가 호스트패스에서 가져오도록 되어있음을 알 수 있다.
kubectl describe -n amazon-cloudwatch ds fluent-bit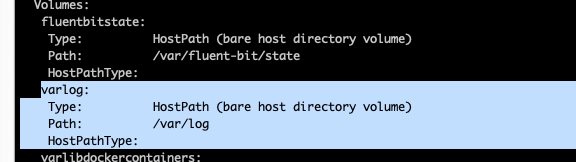
컨테이너 인사이트
클라우드와치 에이전트가 수집한다던 3가지 종류의 로그들이 각각 로그그룹으로 설정되었음이 콘솔에서 확인이 된다.

nginx로그는 applicaion 로그그룹에 잘 수집이 된다.
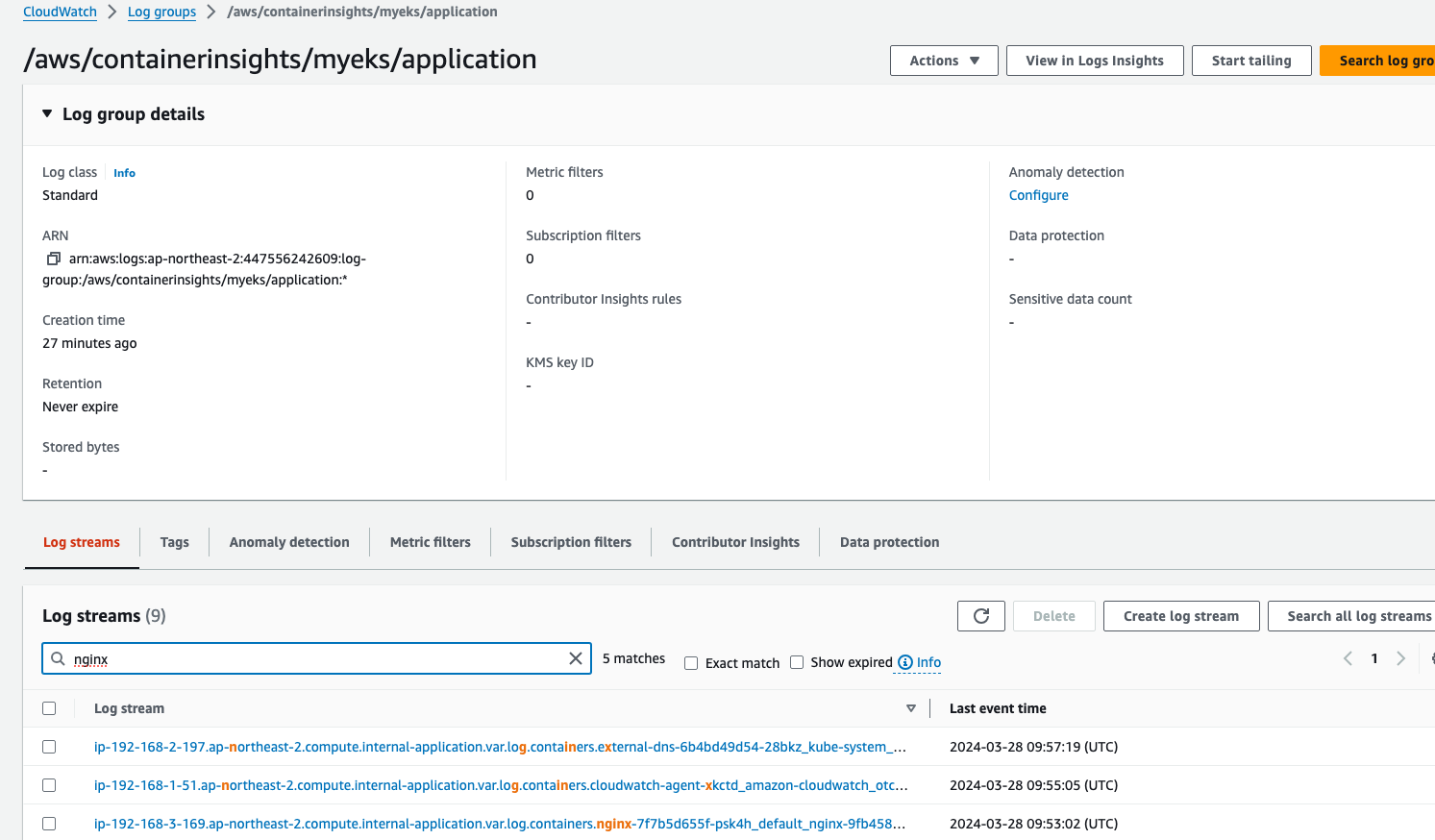
로그 그룹별로 stderr발생 등도 검색이 가능하다. 필요에 따라 샘플쿼리를 찾아 치면된다.
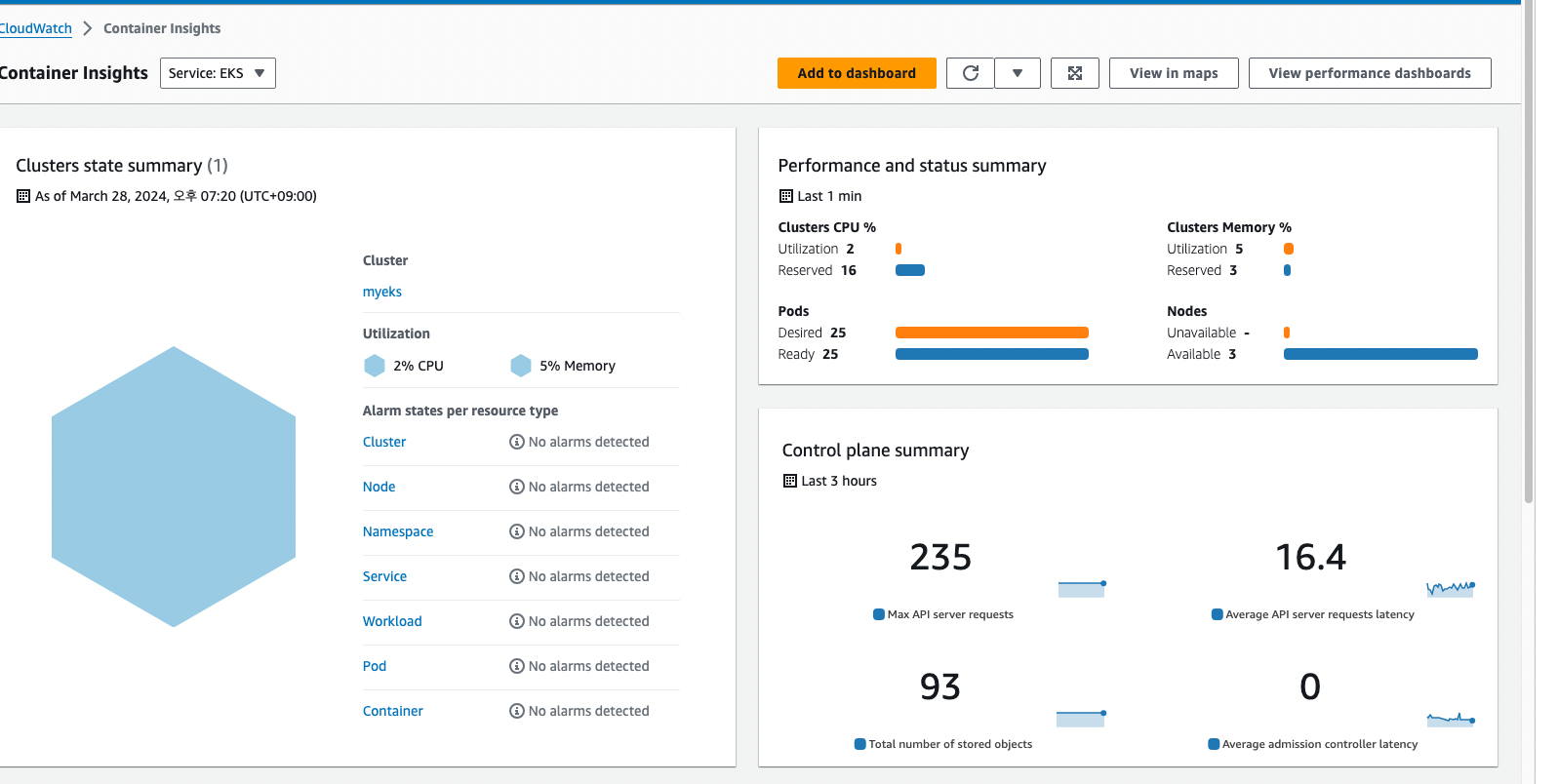
그리고, CloudWatch Container observability를 설치했기 때문에 이렇게 Container Insight도 활성화가 된다.
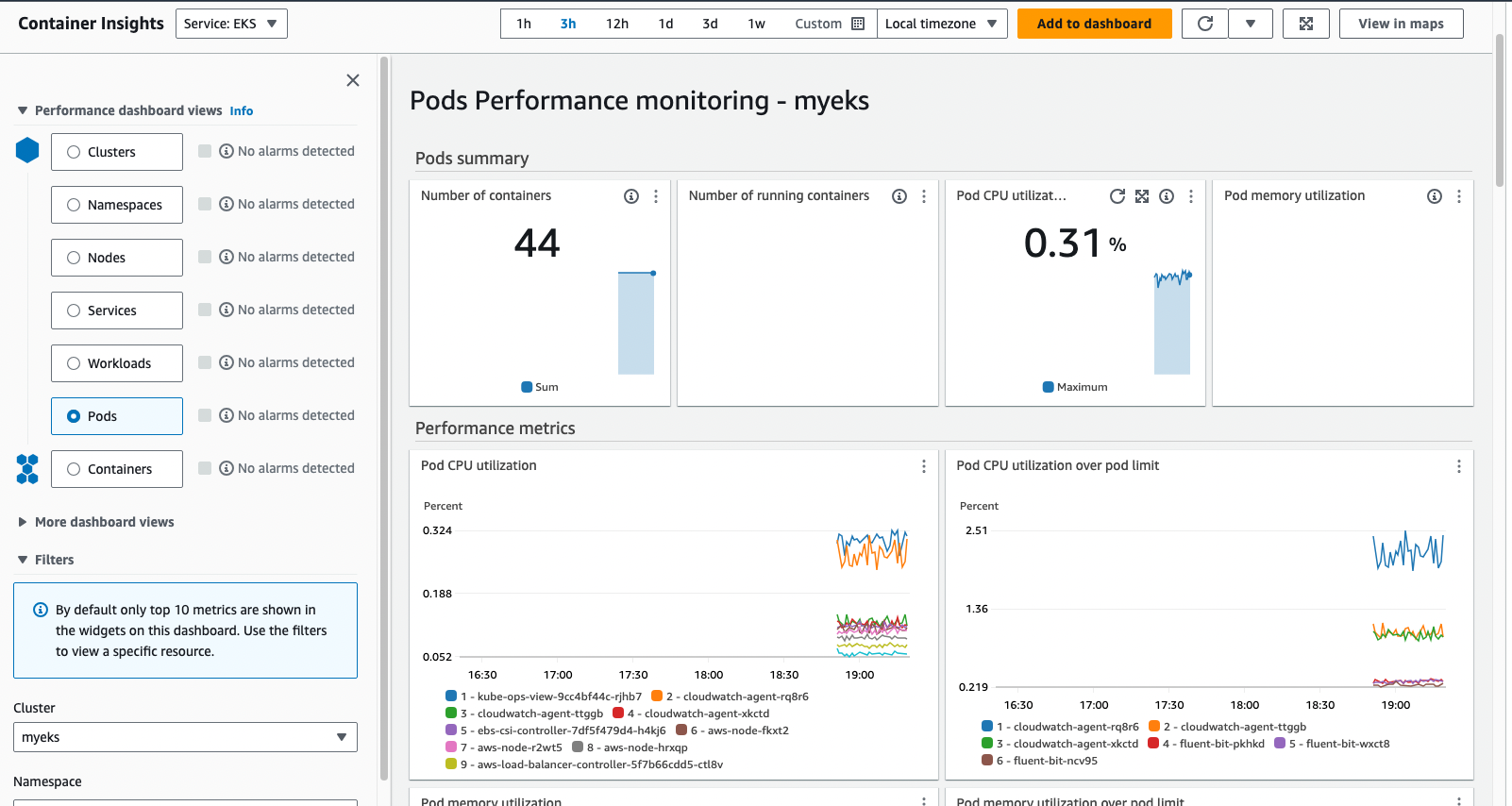
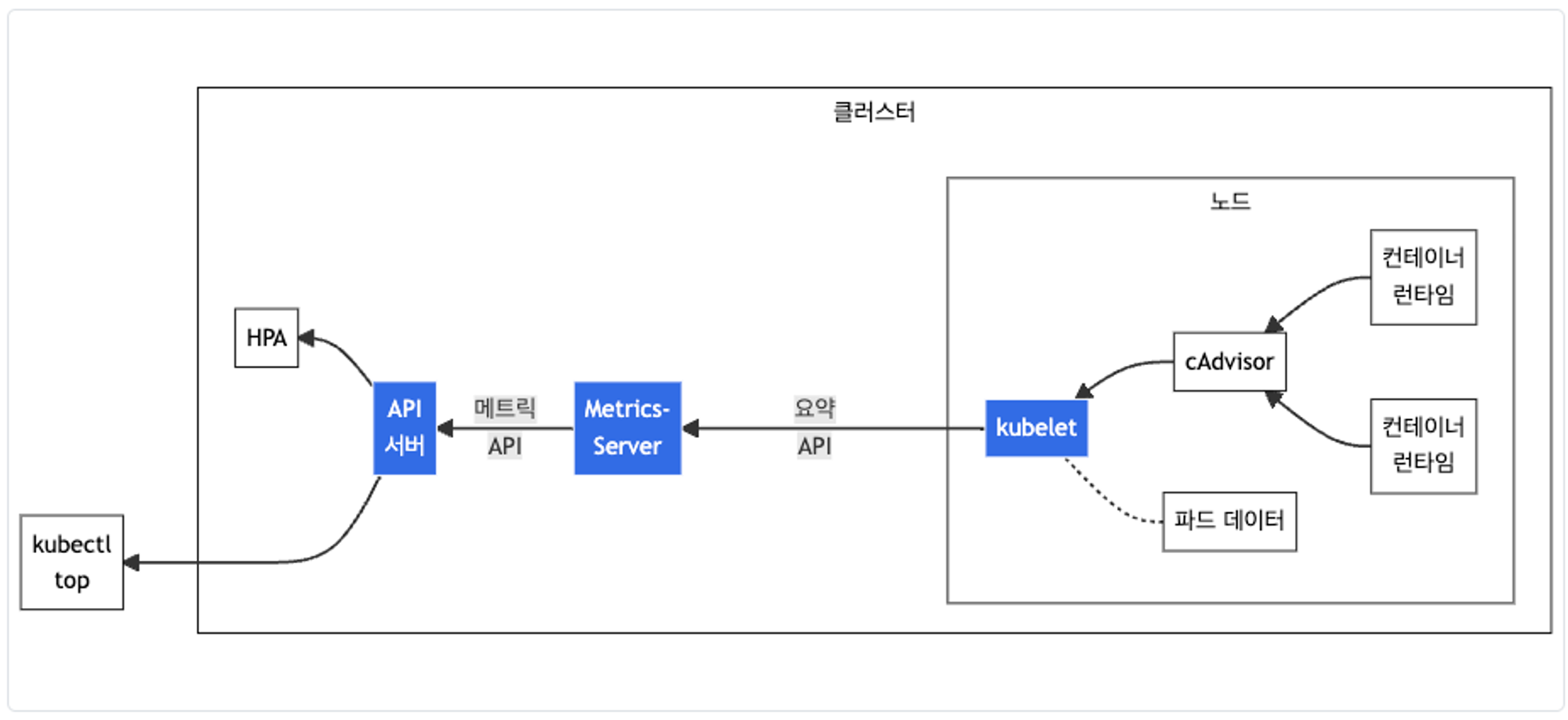
Metrics-server & kwatch & botkube
kubelet으로부터 수집한 리소스 메트릭을 메트릭서버를 사용하여 보여준다.
아래처럼 배포를 한다.
# 배포
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
# 메트릭 서버 확인 : 메트릭은 15초 간격으로 cAdvisor를 통하여 가져옴
kubectl get pod -n kube-system -l k8s-app=metrics-server
kubectl api-resources | grep metrics
kubectl get apiservices |egrep '(AVAILABLE|metrics)'
노드별 메트릭 정보확인
kubectl top node
각 파드 별 메트릭 정보도 볼 수 있다.
kubectl top pod -A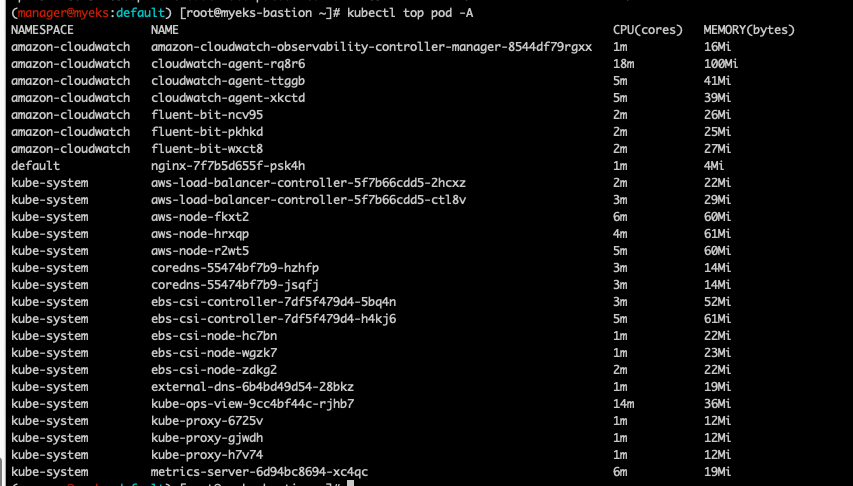
그라파나
그라파나는 TSDBD의 데이터를 시각화하고, 다댱한 데이터 형식을 지원한다.
실습을 위해 이미 설치한 프로메테우스 스택에 그라파나가 포함되어있다.
echo -e "Grafana Web URL = https://grafana.$MyDomain"
다양한 데이터를 그라파나에서 시각화할 수 있는데, 대표적인게 프로메테우스이다.

현재 데이터소스에 잡힌 주소가 아래처럼 있는데, 이 주소는
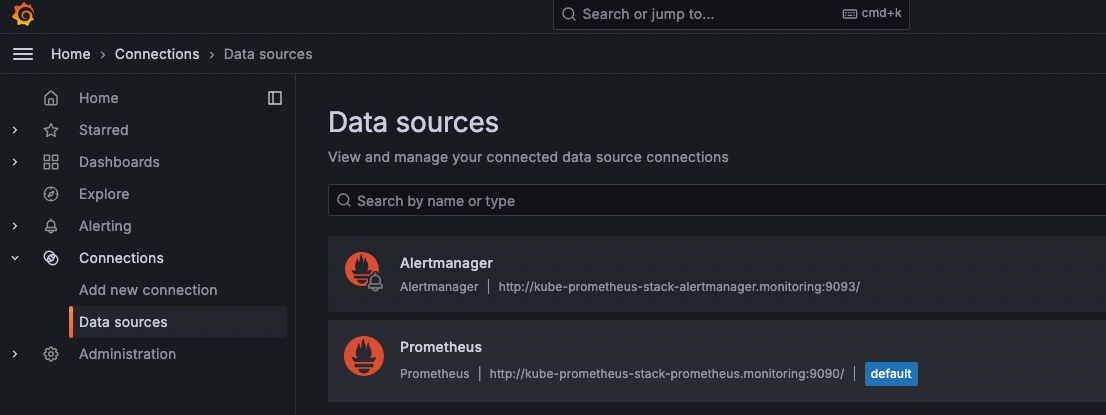
아래 배포된 서비스의 주소이다.

실제로 아래처럼 테스트용으로 파드하나 생성해 접속해서 위 kube-prometheus-stack-prometheus.monitoring을 nslookup해보면
# 테스트용 파드 배포
cat <<EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: netshoot-pod
spec:
containers:
- name: netshoot-pod
image: nicolaka/netshoot
command: ["tail"]
args: ["-f", "/dev/null"]
terminationGracePeriodSeconds: 0
EOF
kubectl get pod netshoot-pod
# 접속 확인
kubectl exec -it netshoot-pod -- nslookup kube-prometheus-stack-prometheus.monitoring10.100.239.189로 프로메테우스 서비스의 ip가 나온다. (http://kube-prometheus-stack-prometheus.monitoring:9090/가 나온다.)

즉 그라파나의 데이터소스로 프로메테우스 서비스가 연결되어있음이 확인되었다.
대시보드 사용하기
대시보드에 들어가 오른쪽에서 Import선택
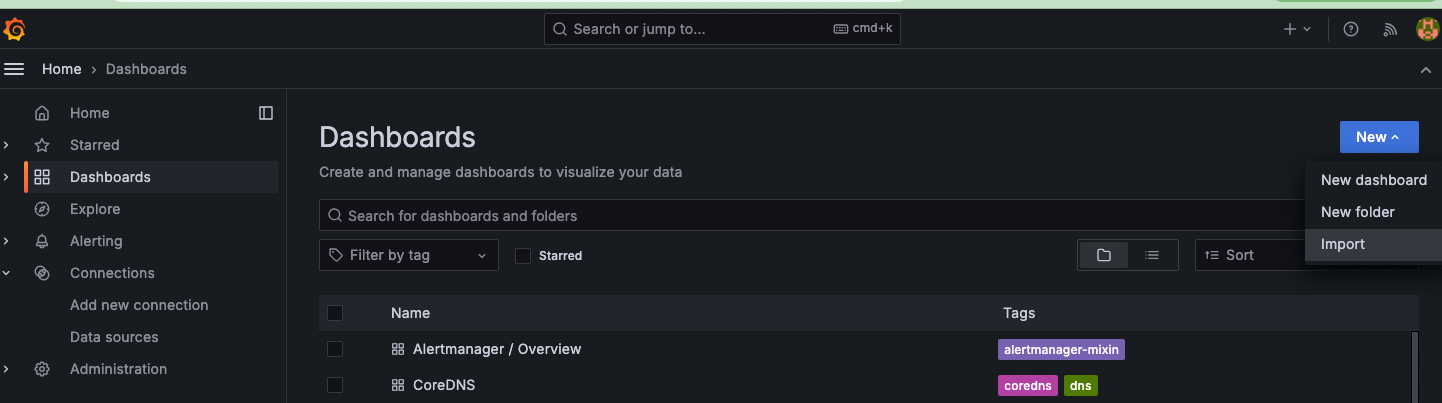
유명한 대시보드를 가져온다.https://grafana.com/orgs/imrtfm/dashboards
스터디에서 추천해준 15757과 17900 를 입력해주고 Load를 눌러준다.
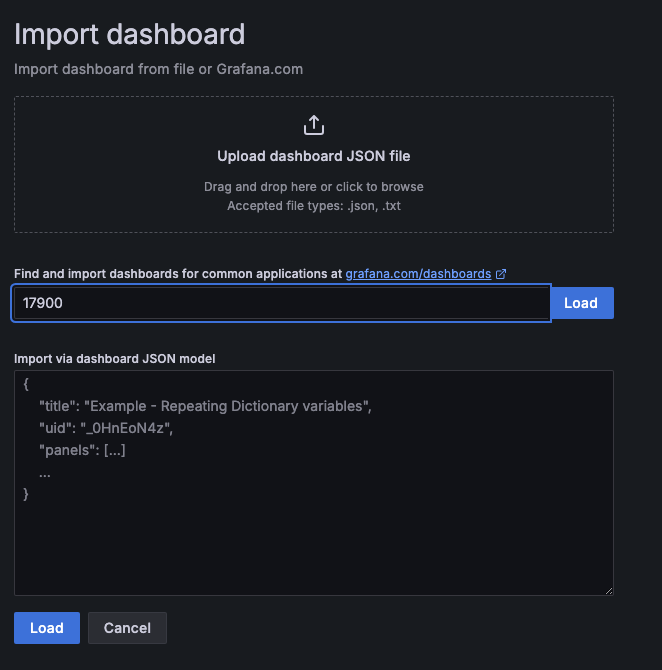
데이터소스에서 아래처럼 아까 생성된걸 확인한 프로메테우스 데이터소스를 연결해주면
완성!ㄷㄷ
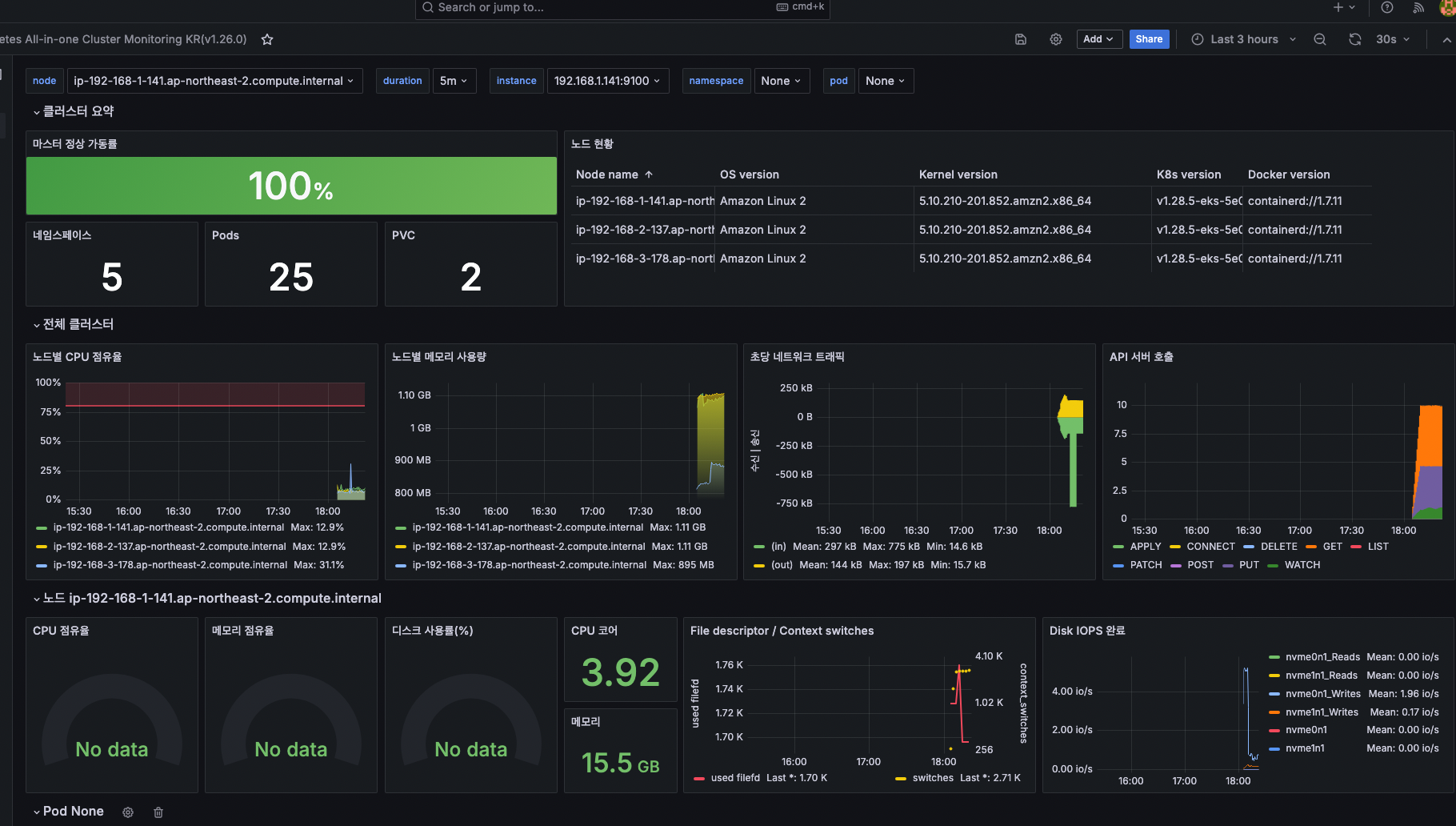
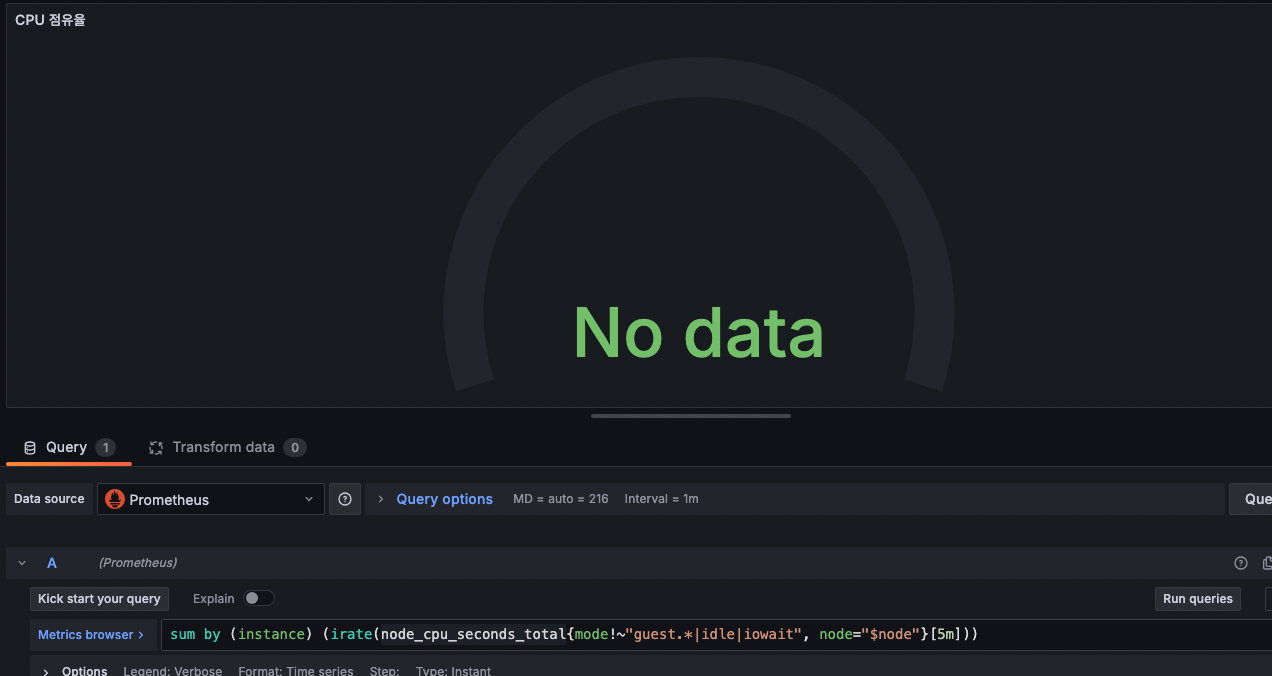
현재 정보가 안나오는데, 수정해보자.

edit에 들어와서 promql을 보자.
직접 프로메테우스 쿼리창에서 검색해보면
node_cpu_seconds_total{mode!~"guest.*|idle|iowait"}
는 잘 나온다.

근데 아래는 정상적이지 않다.
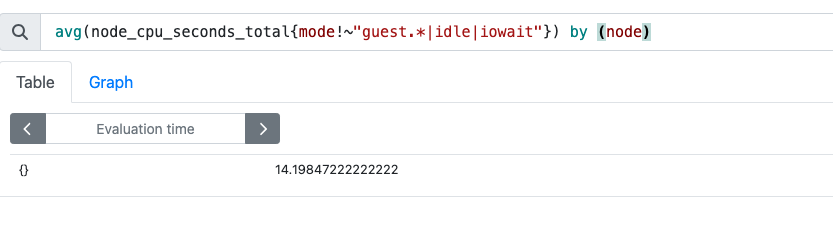
node대신 instance로 해보니 잘나온다.

즉 샘플대시보드에서 제공해주는 용어와 eks에서 사용하는 용어의 차이때문에 인식이 안된것이므로,
node대신 instance라고 써주면 잘된다.
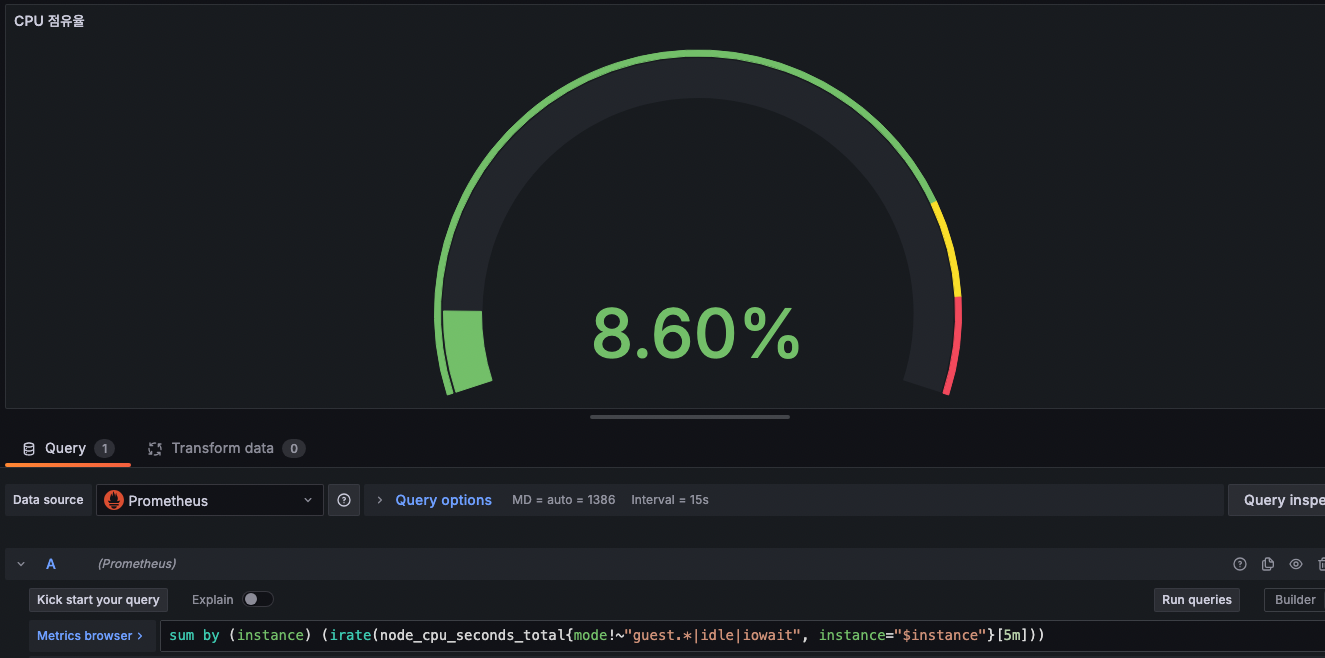
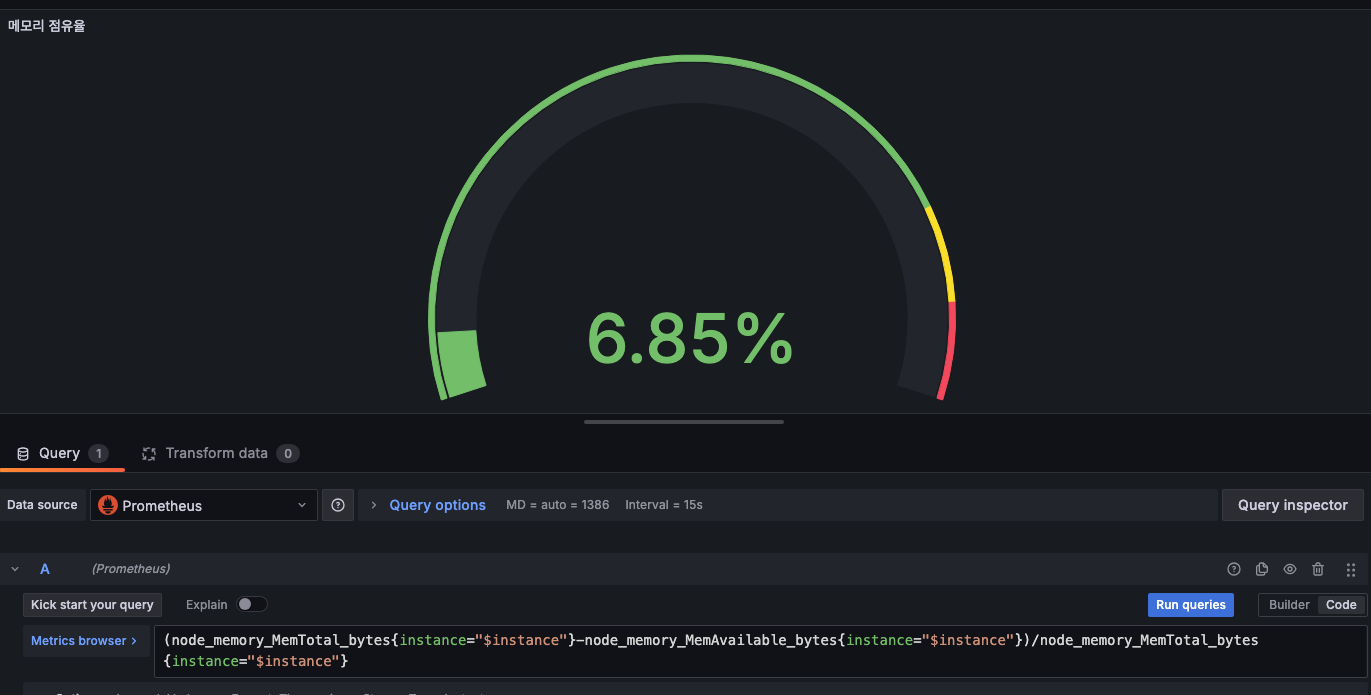
메모리와 디스크사용률도 node대신 instance로바꿔주자
-> 변신!!
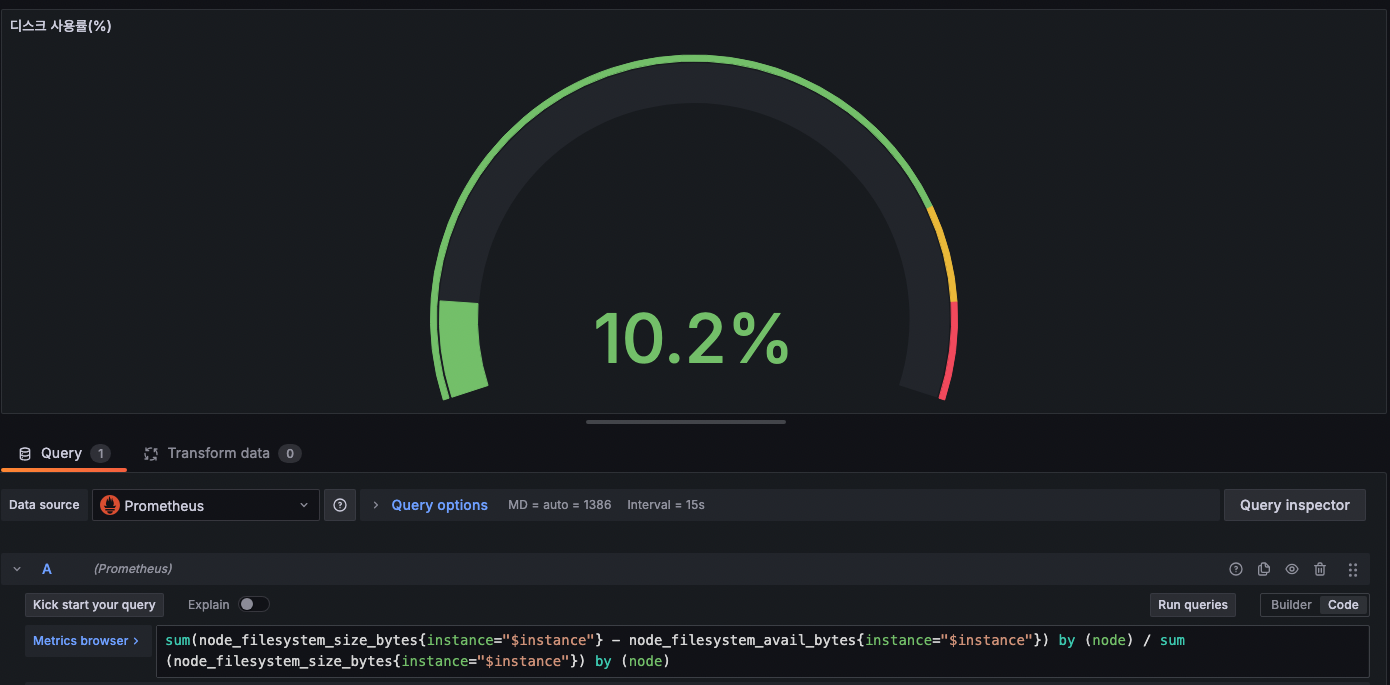
패널 만들어보기
- [Time Series] 노드별 5분간 CPU 사용 변화율
sum(rate(node_cpu_seconds_total[5m])) by (instance)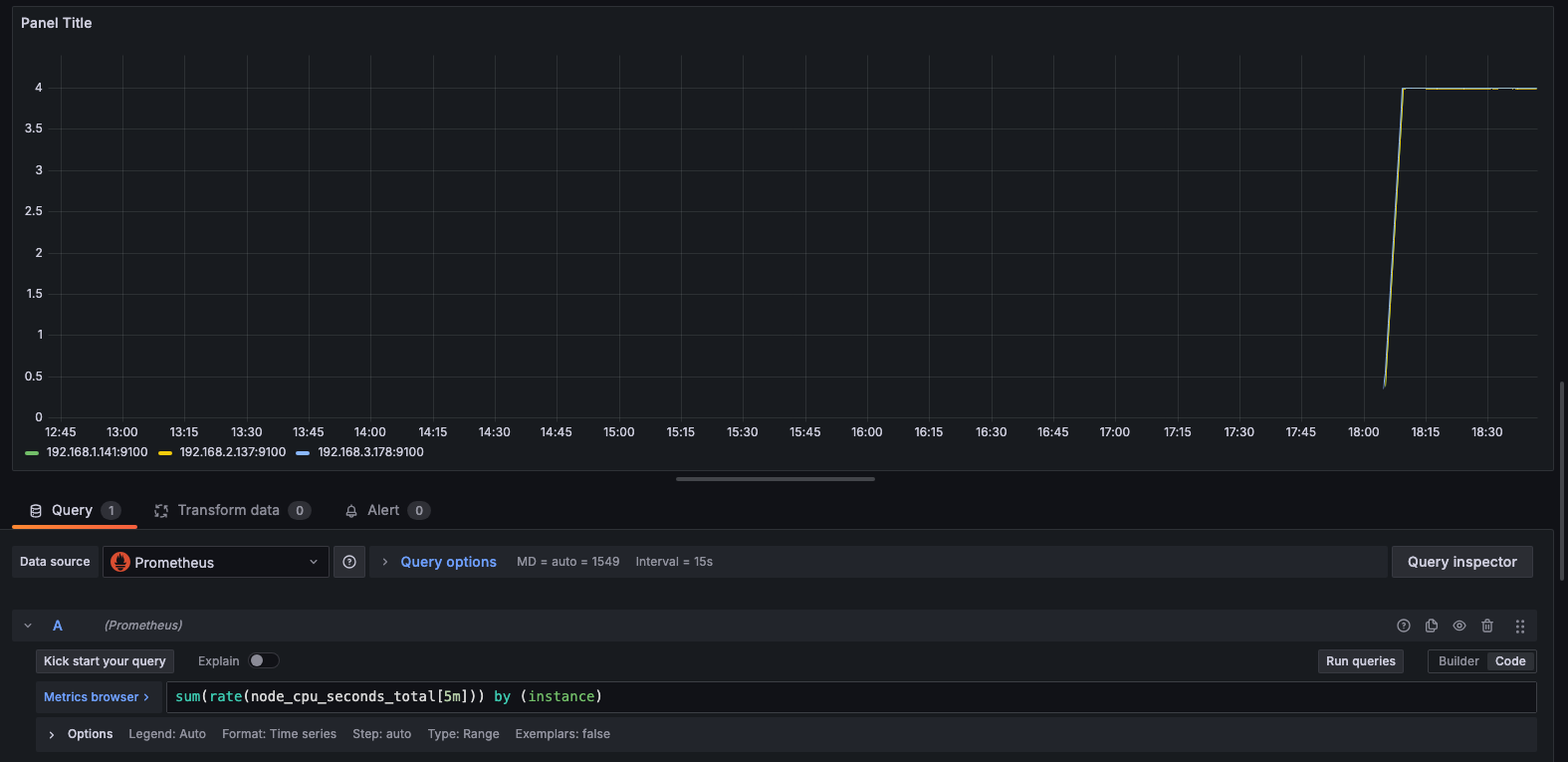
- [Bar Chart] 현재 시점 namespace 별로 deployment가 몇개인지
count(kube_deployment_status_replicas_available) by (namespace)이때, 아래 options에서 Format은 table, Type은 Instant(=현재시점)로 해줘야 한다.
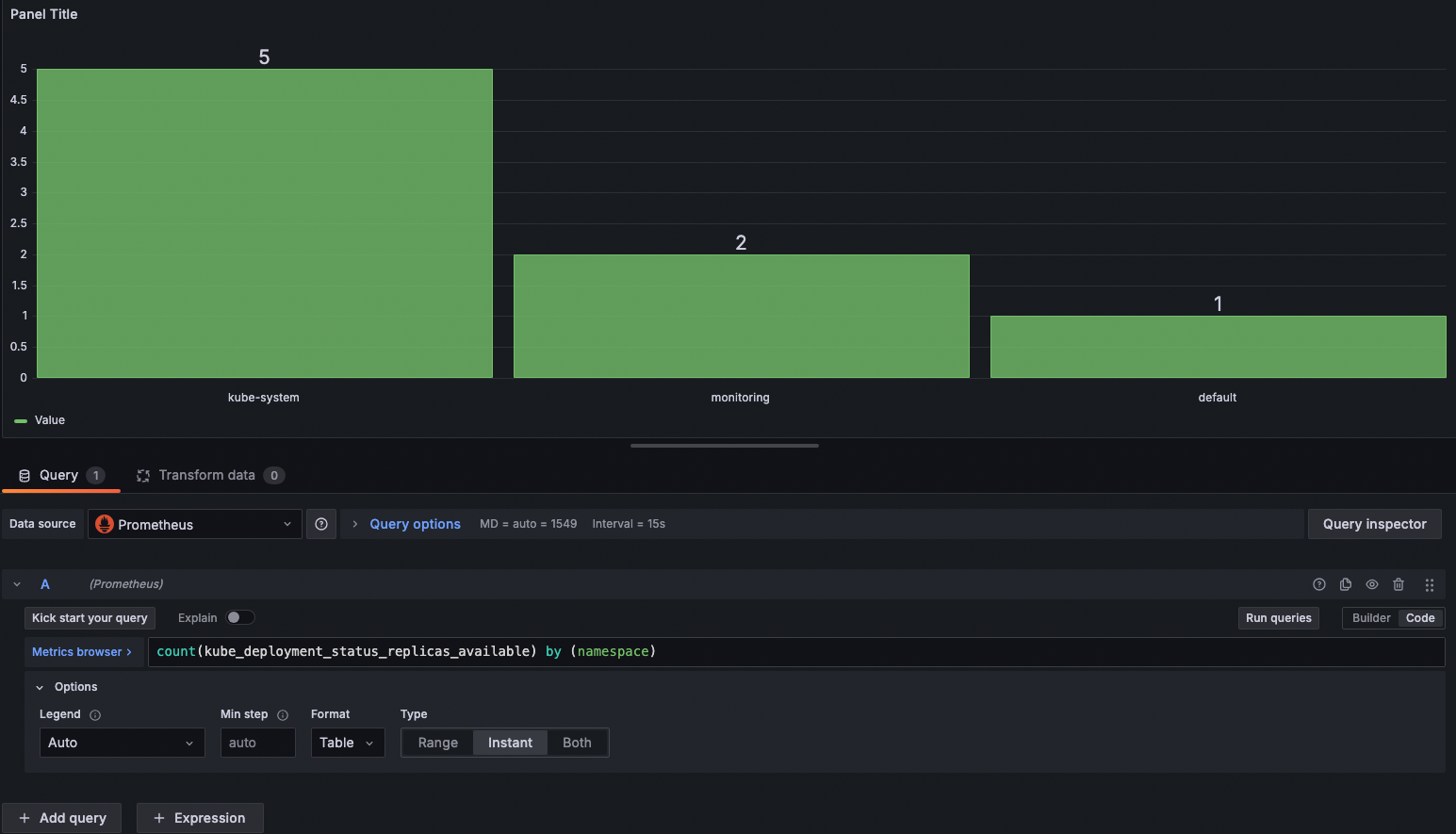
- [Bar Chart] nginx 파드 수
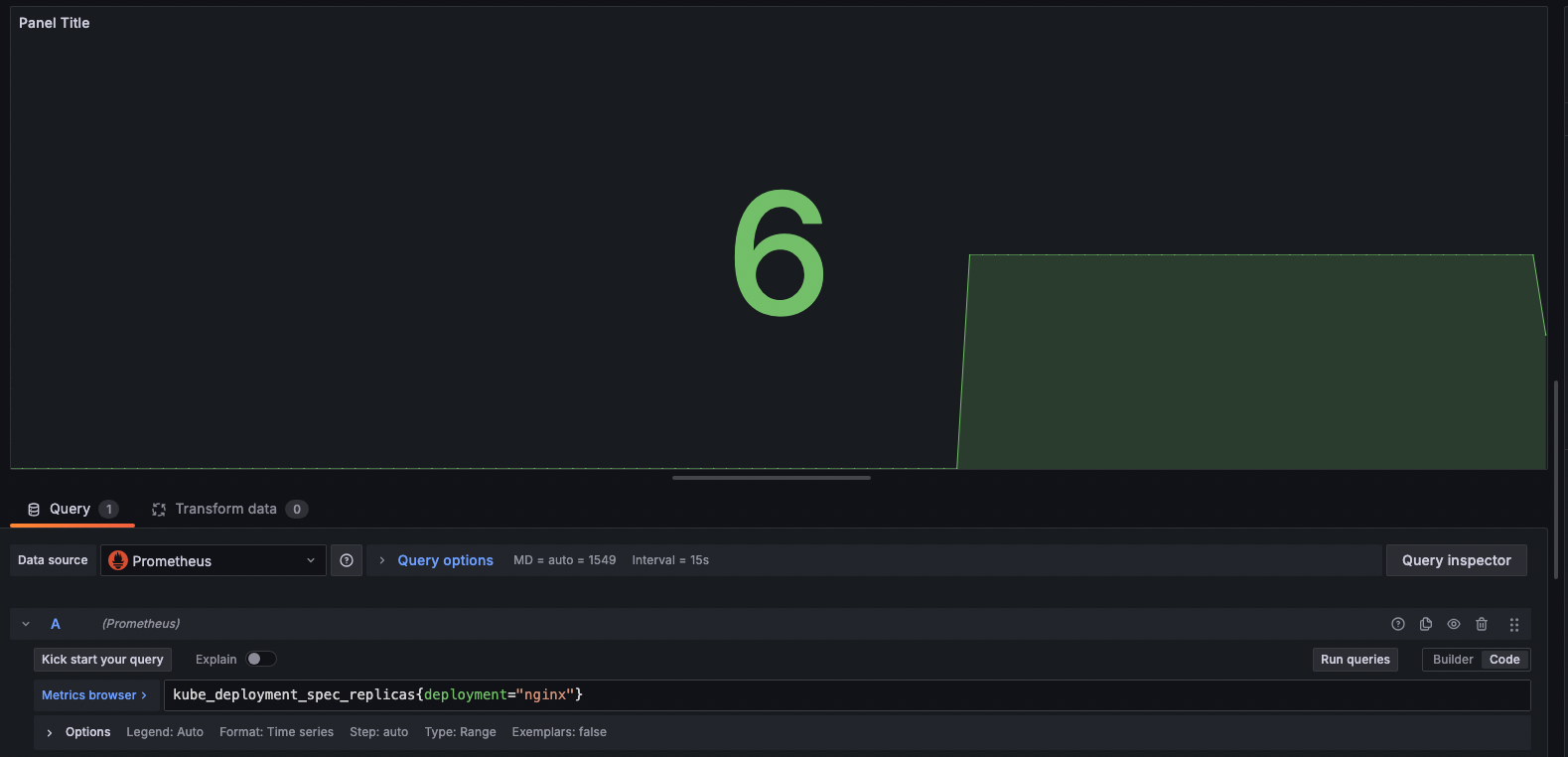
kube_deployment_spec_replicas{deployment="nginx"}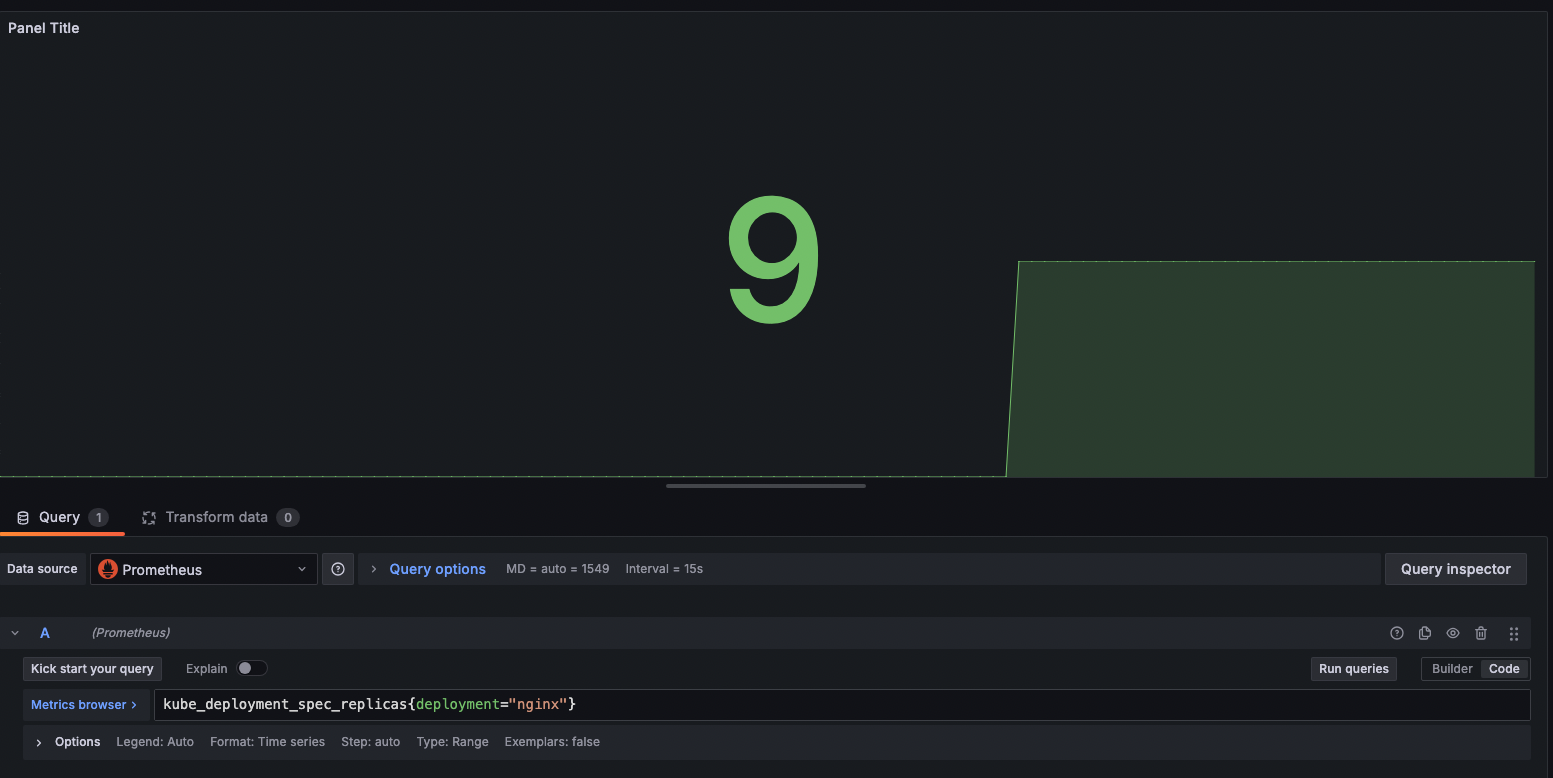
실제로 6개로 줄이면 잘 반영이 된다.

- [Gauge] 노드 별 1분간 CPU 사용률
1 - (avg(rate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance))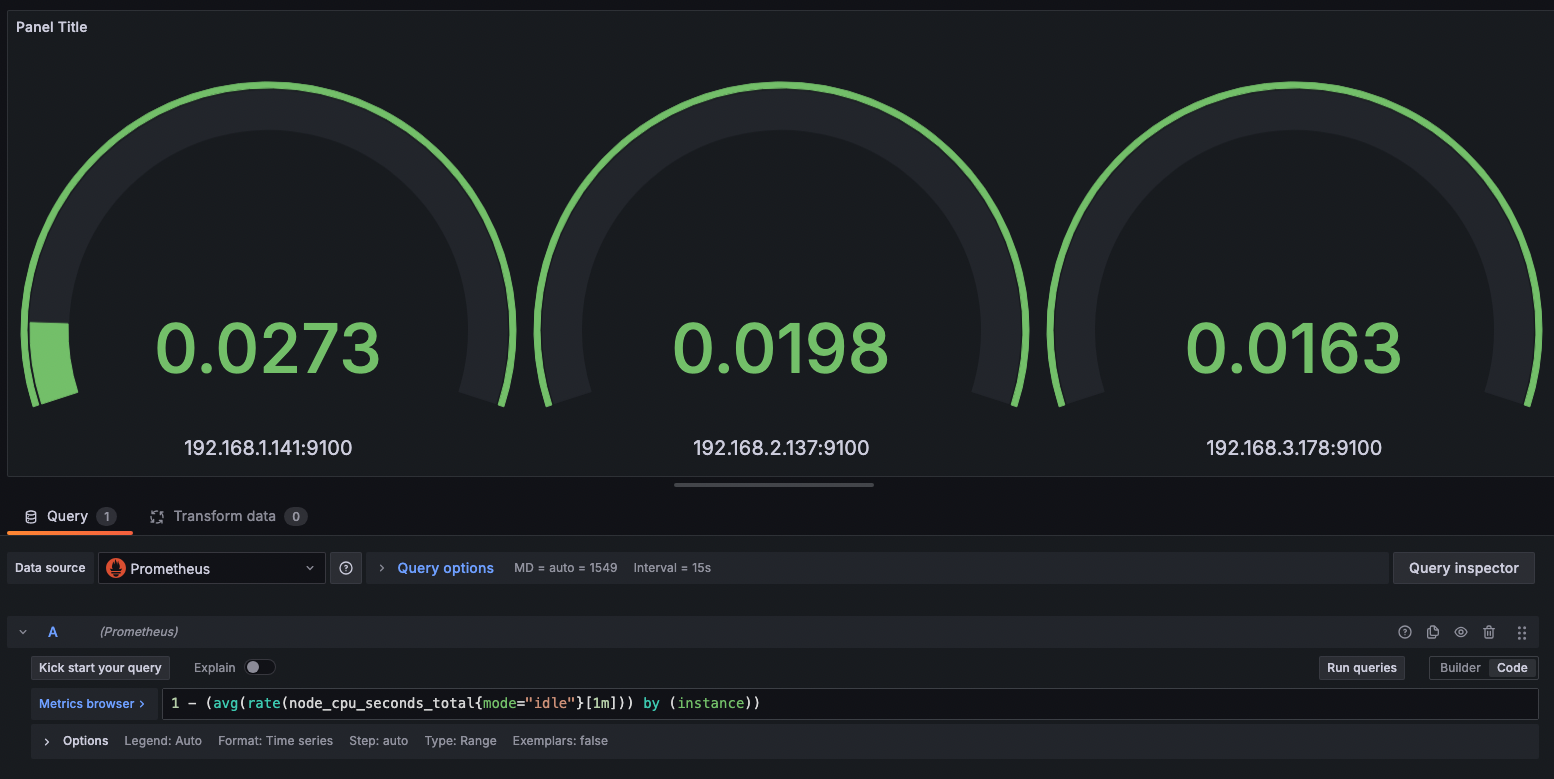
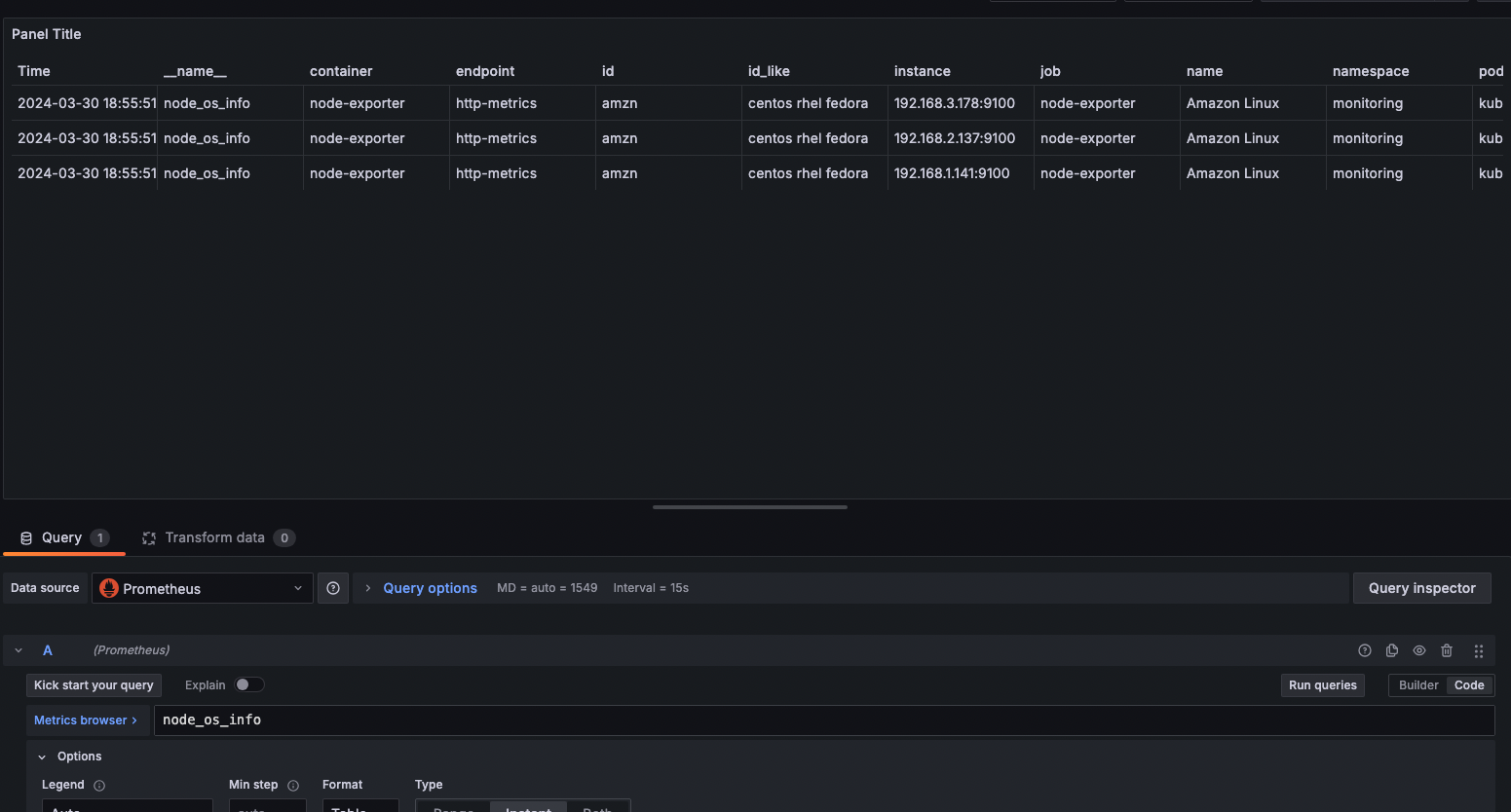
- [Table] 현재 시점 노드 OS 정보
node_os_info이것도 현재시점이니 options에서 instant를 선택해주고, format은 table을 선택해준다.
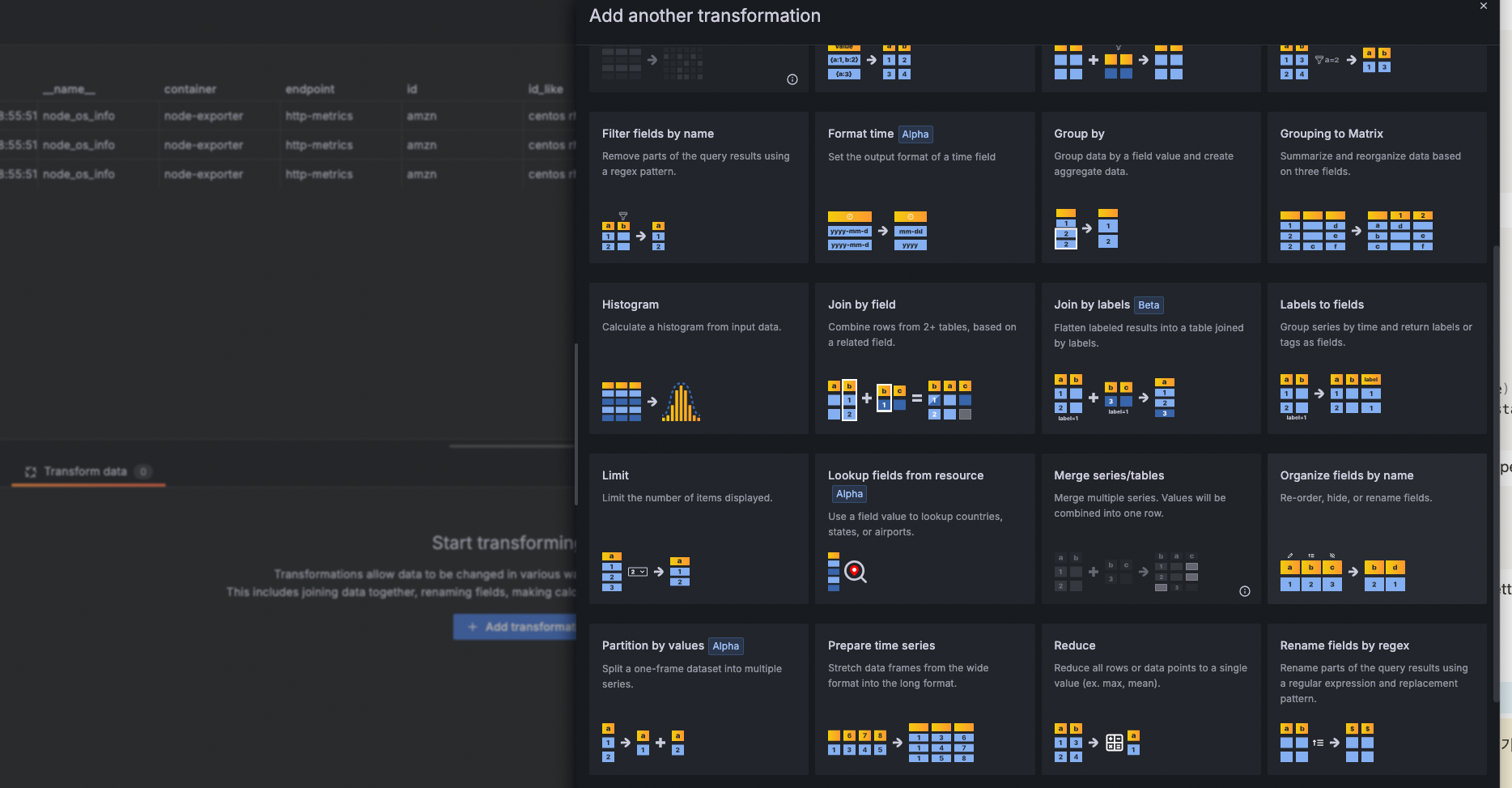
근데 필드값이 너무 많으므로, Organize fields by name을 선택하여 수정해준다.
아래 화면 후 나오는 선택화면에서 Organize fields by name : id_like, instance, name, pretty_name 만 골라주면된다.
깔끔해졌다

그라파나 Alert
아래 화면에서 new alert를 눌러 생성한다.
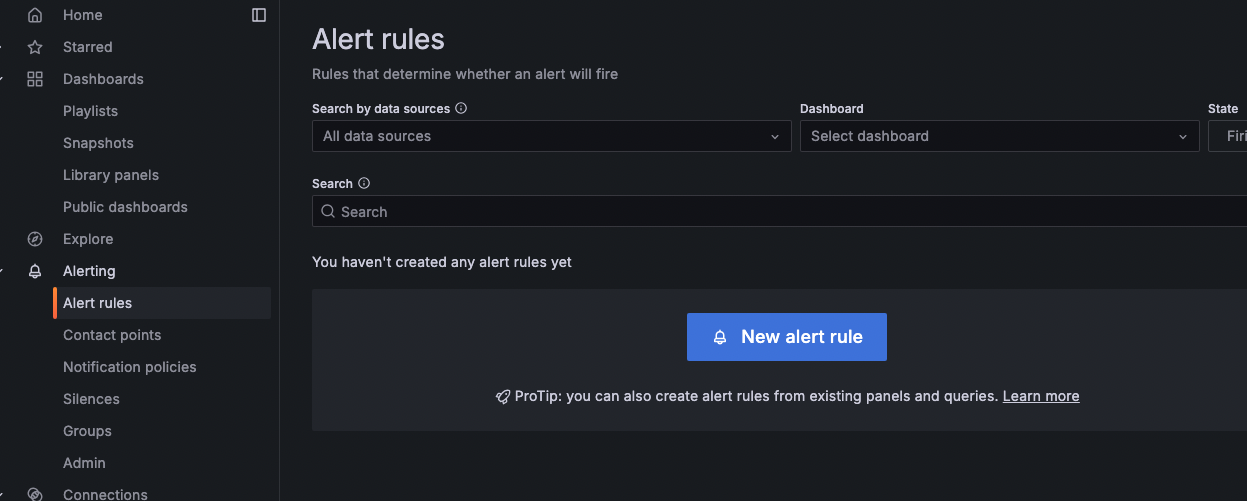
그리고 스터디에서 제공해준 아래 자료대로 설정을 해준다.
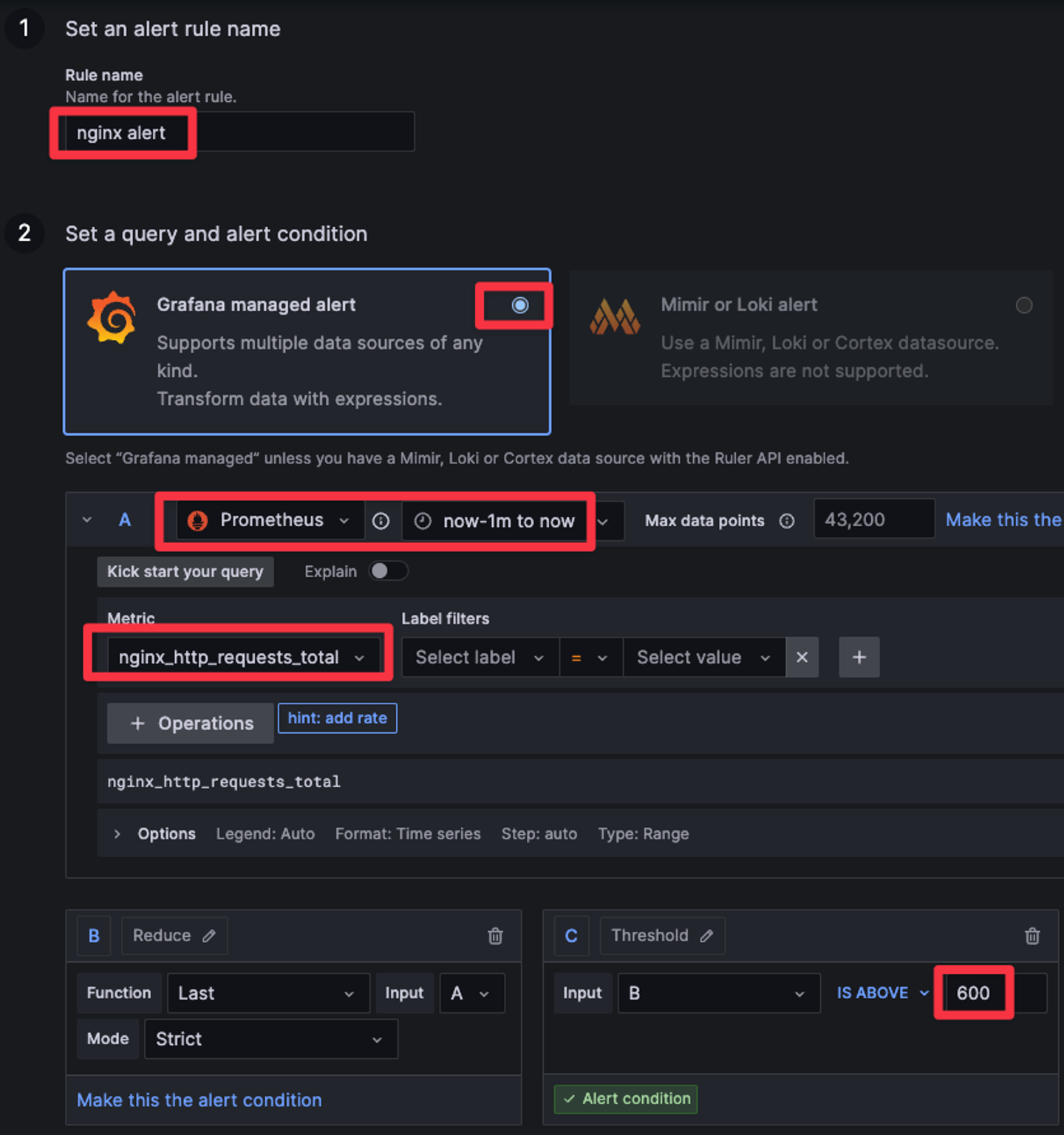
그리고 Cotact point를 생성하며 slack을 선택해준다.
나는 내 워크스페이스 슬랙채널에 연락을 주도록 하였다.
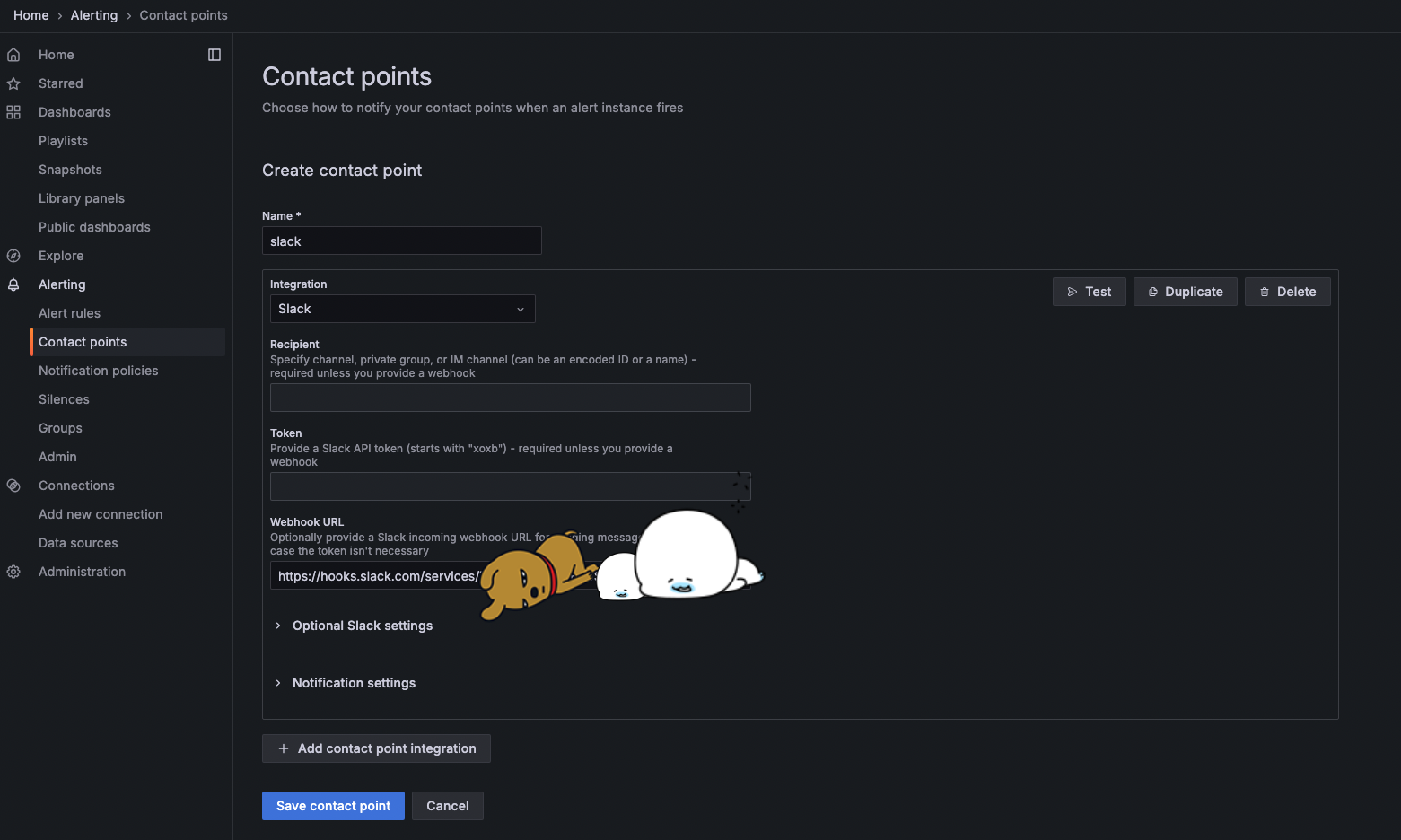
그 후 notificatin policy를 설정해주고
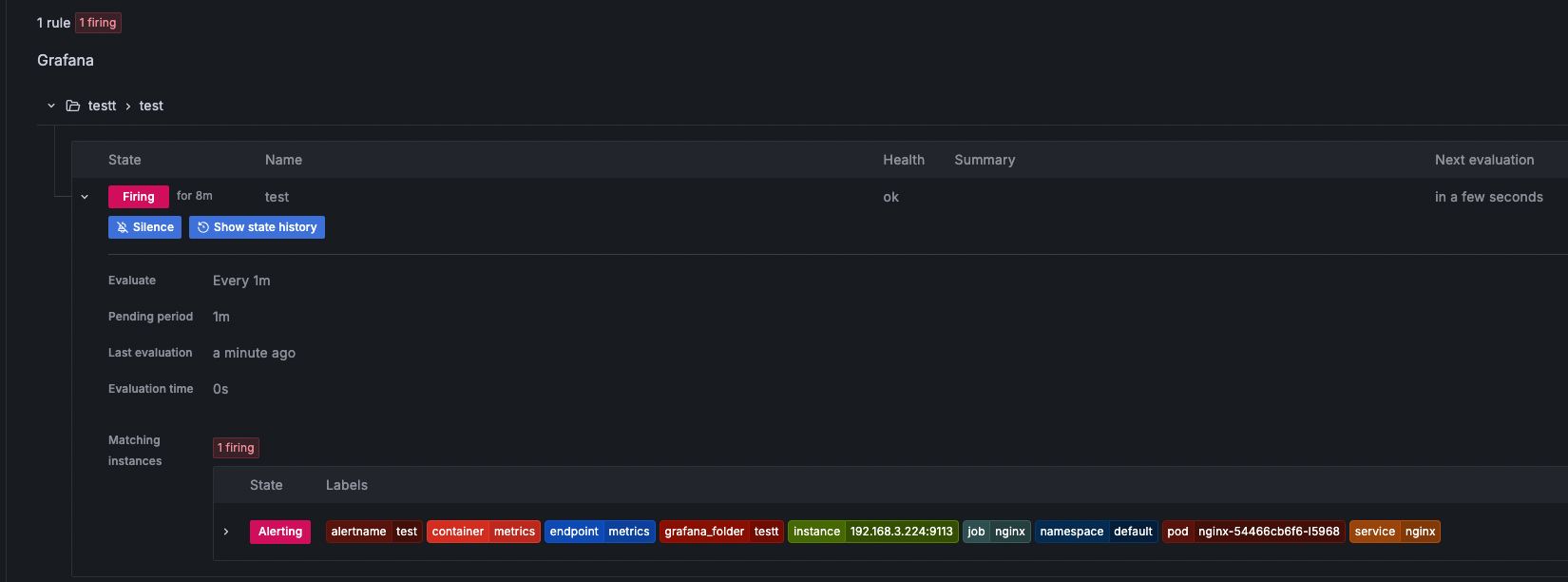
nginx에 무한대로 요청을 날리면
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; done알람이 발생하고 슬랙에 알림이 오는게 확인된다.

'개발삽질 > 잡다한 개발기록' 카테고리의 다른 글
| [EKS 스터디-6] EKS Security (0) | 2024.04.13 |
|---|---|
| [EKS 스터디-5] EKS Autoscaling (0) | 2024.04.03 |
| [EKS 스터디-2] 하) EKS 네트워크 공부 (0) | 2024.03.16 |
| [EKS 스터디-1] 클러스터 구조와 기본사용법 (0) | 2024.03.06 |
| [sql]프로그래머스 sql문제정리1(select, 집계함수, group by) (0) | 2022.03.11 |




댓글